Our goals for the fellowship are to train more data scientists and to get them working on problems that really matter. Lots of folks have been asking about how we’re doing that.
Data scientists are a hybrid group with computer science, statistics, machine learning, data mining, and database skills. These skills take years to learn and there’s no way to teach all of them during a few weeks.
Instead of starting from scratch, we decided to start with students in computational and quantitative fields – folks that already have some of these skills and use them daily in an academic setting. And we gave them the opportunity to apply their abilities to solve real-world problems – and to pick up the skills they’re missing.
Applied science
There’s a learning curve, of course. But we think the best way to learn any applied science is to get your hands dirty. That’s why we spent the past couple of months scoping and prepping analytics projects with governments and nonprofit organizations for fellows to dig into.
Working on real projects is the only way to pick up the practical skills that round out the data science skill set: understanding a new domain, turning a vague problem into one that can be solved using data science tools, and building solutions that get used.
Some our fellows excel at creating algorithms that learn from data. Others are great at analyzing social networks, parsing natural language, or writing software.
But nobody can do everything. So we built diverse teams for each project.
This setup presented us with two challenges:
- Effective teams require close collaboration.
-
To bridge the diversity of fellow backgrounds, we needed a common toolbox.
So we invited our friends from Software Carpentry – a nonprofit which teaches scientists to code – to run a tech bootcamp for our fellows.

Collaboration tools
To get fellows working together, instructor Elliott Hauser (picture above) introduced them to git and github, tools which make it easy to share code and collaborate. Though popular in the world of software engineering, few fellows had used them before. (Students often use subversion or cvs for version control.)

Eliott also got fellows pair programming, where two people code together on one computer.
“Individually, our knowledge is like swiss cheese. But collectively, we know all these different things we can share,”
says fellow Skyler Whorton. “It’s a lot more beneficial than taking individual classes.”
Common toolkit
Every computational or quantitative field has its favorite tools. Our fellows are familiar with dozens of technologies:
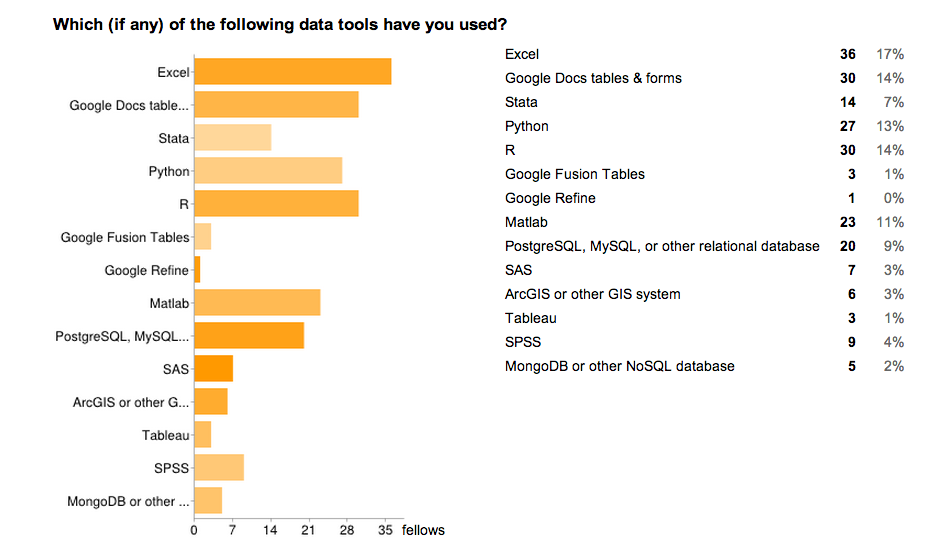
To give everyone a lingua franca, we did workshops on python and R.
As a general purpose programming language, python is useful for dealing with data. (Click here for a good overview of its strengths for data science.)
R is the go-to free tool for statisticians, and has tons of advanced statistical models, machine learning algorithms, and data visualization libraries.
We focused on using python for data analysis. Although most fellows were familiar with python…

…not all of them had used numpy and pandas, powerful libraries for scientific computing.

Fellows were also exposed to ggplot2, a library for creating beautiful data graphics.

Instead of tailoring the sessions to different ability levels, we experimented with giving everyone a shared experience. This approach had its downsides:
“We all come from so many different backgrounds and levels of knowledge that sometimes it felt like not everyone was getting same amount out of it,” says fellow Breanna Miller. “But I think trying to lay the groundwork so we’re all on the same page was really helpful.”
Of course, nobody learns a new tool in a day. The point was to give fellows a whirlwind overview of the tools available to them, so they can go deep on the ones they find useful over the course of the summer.