There are thousands of organizations around the country that are dedicated to helping people in need. Yet despite those good intentions, few of those organizations are scientifically rigorous in evaluating their strengths and weaknesses in order to make changes to maximize positive impact in as many people as possible. The reasons are easy to understand: a thorough evaluation is time-consuming, expensive, requires skilled scientists to administer and may produce uncomfortable results. But in a time where government and private funders want to see more concrete benefits from their investment, non-profits are increasingly pressured to demonstrate – and quantify – their impact.
For four decades, Nurse-Family Partnership (NFP) has stood out among social need organizations as a model for science-based self-evaluation. Founded by developmental psychologist David Olds in the 1970s, NFP sends nurses to the homes of low-income, first-time mothers during their pregnancy and the first two years of the child’s life. Before scaling up nationally, NFP rigorously tested its methods with randomized controlled trials, the gold standard of clinical research, in three very different locations (Elmira, NY, Memphis and Denver) with different racial mixes, in three different decades.

It has been 19 years since the last of those studies began, and NFP chapters have since expanded to 43 states. The broader implementation – and increased pressure for evidence-based accountability from federal funders – creates the need for new evaluations. But the expense of running new randomized controlled trials in all of those locations would be astronomical, so the organization is interested in new methods they can use to measure their national effect. For their summer project, Data Science for Social Good fellows Joe Walsh, Adam Fishman and Emily Rowe (along with mentor Nick Mader) are helping NFP find a new data-driven way of assessing their impact, creating a new process that can be used by NFP and similar organizations to assess their actions, demonstrate results to funders and find new ways of improving the program in the future.
Finding the Right Match
The primary question that NFP would like to answer is, “what would have happened if the mother had not enrolled in NFP?” In the randomized controlled trials, this could be easily settled by randomly assigning qualified mothers into treatment and control groups and comparing the outcomes. But demonstrating the program’s effectiveness on a national scale is very difficult. While NFP has collected data on every one of its nurse home visits since 1996, NFP does not collect information on the ideal control population: mothers who they do not serve.
One could compare the mothers and children enrolled in NFP to the general population, but that would not be the most accurate comparison. Aside from the low income that qualifies a pregnant woman for enrollment, NFP mothers are also less likely to be a high school graduate, less likely to be married, more likely to be from a minority group and younger than the average U.S. mother. These characteristics plausibly affect the wellbeing of the mother and child independently, so NFP mothers should be compared to non-NFP mothers with similar characteristics.
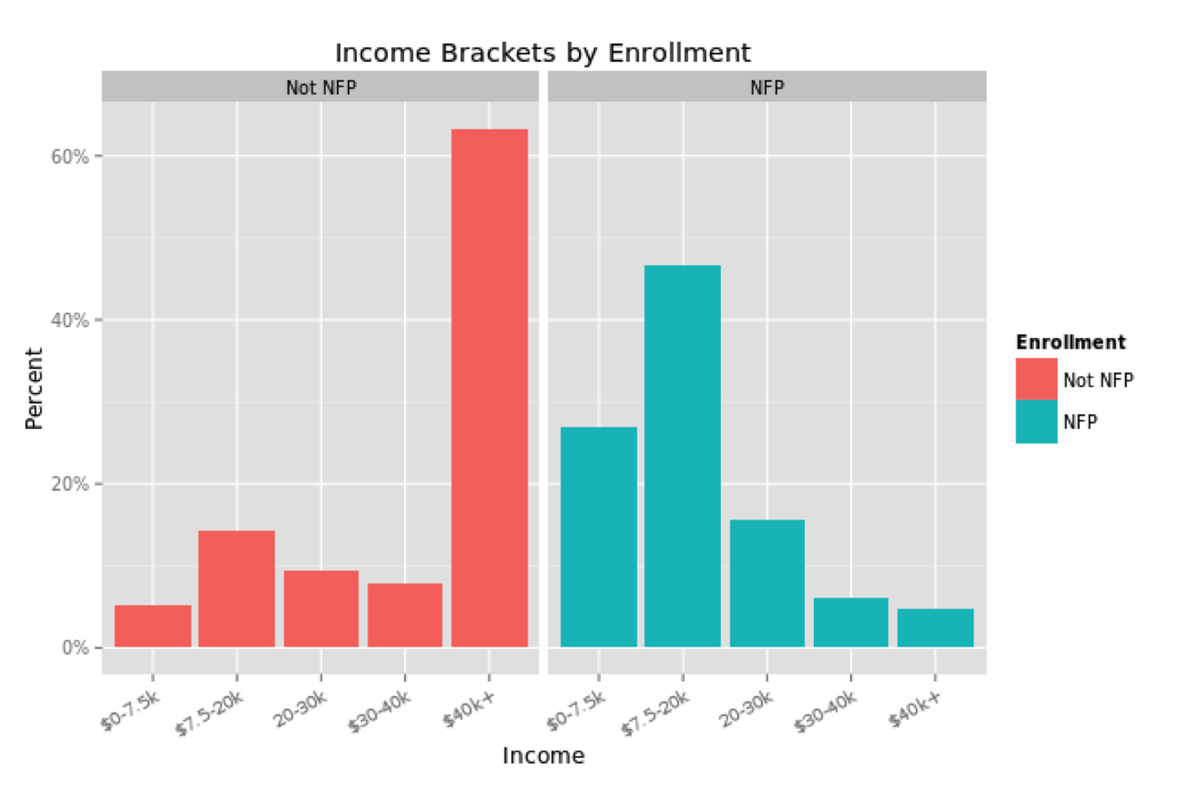
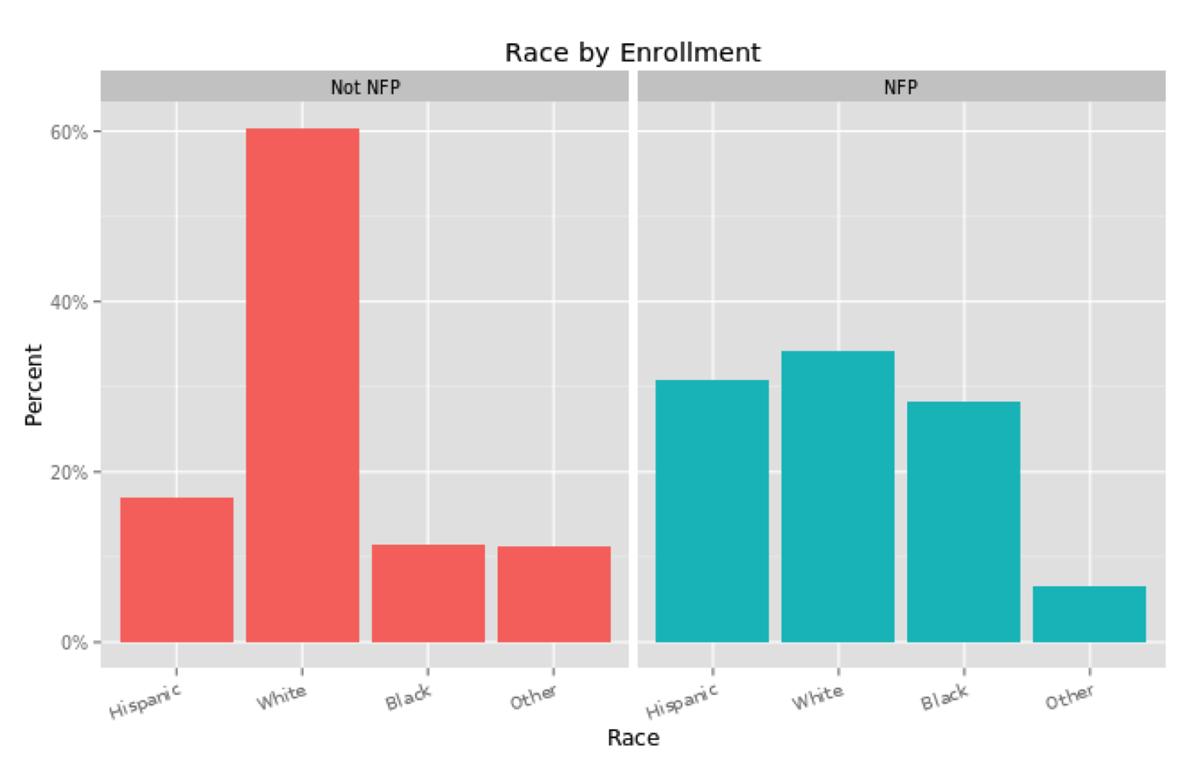
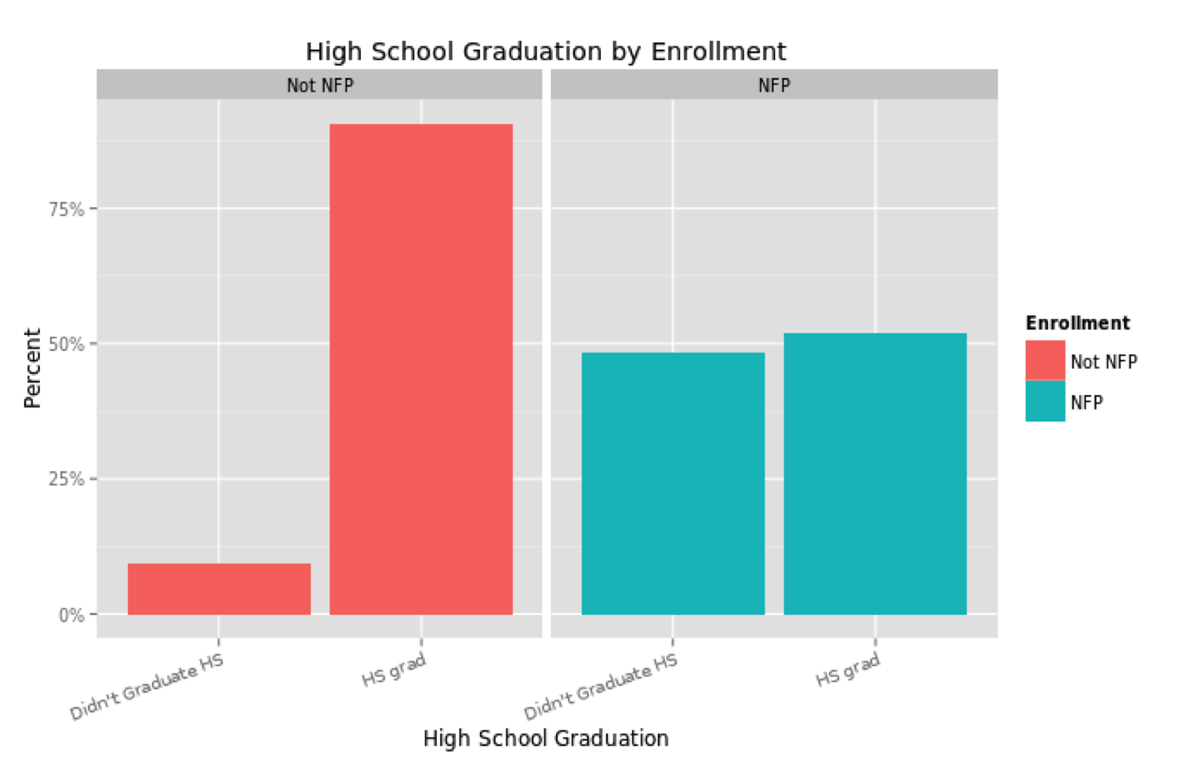
These differences would naturally be expected to influence a mother and child along the results that NFP most cares about: birth outcomes, the economic self sufficiency of the mother and the child’s health and development. So the NFP team applied propensity score matching to their analysis, in order to compare mothers enrolled in NFP to mothers in the general population who closely match their demographics. While it may be simple to compare groups according to one characteristic, such as race or income, matching over several measures quickly becomes statistically challenging.
“If you want to identify two people as similar for statistical purposes, it’s very hard if you have several characteristics about them,” said Fishman. “What propensity score matching does is, instead of saying ‘are these two people exactly the same?’ you say ‘which people will have the closest likelihood of being part of this program?'”
Instead of finding exact matches, their analysis (which uses R and its “Matching” package) can assign a propensity score to each subject in a dataset – the probability that, given their combination of characteristics, the mother would qualify for NFP. So if a mother in a non-NFP dataset is calculated to have had a 70 percent chance of enrolling in the program, she can be considered a match for an NFP mother who also had a 70 percent chance of enrolling, and a more accurate comparison point.
“It’s odd because you’re predicting the probability that they’ll be in NFP, while at the same time you know whether they were in NFP or not. You’re basically saying, ‘how much do you look like someone who is in NFP?’,” Rowe said.
Matching alone does not create a perfect control group. The team does not have data on every characteristic that could conceivably impact the outcomes in question, including “dark matter” data points like neighborhood qualities and characteristics like motivation or ambition. If these qualities are not balanced between the participants and nonparticipants in the analysis, that imbalance could affect the accuracy of impact measurements. However, since a randomized controlled trial is often not possible at the scale of NFP’s full programs, the team’s goal is to quantify NFP’s impacts as accurately as possible and answer a question that is critical for national social policy.
If The Dataset Fits, Use It
For finding these matches, it would be ideal if there was a single, accessible, national dataset containing all of the relevant characteristics and outcomes for mothers and children in the United States. But alas, there is not, so the NFP team spent the first few weeks of the fellowship seeking datasets that they could use to create suitable matches and compare individual outcomes of interest, such as immunization, child developmental markers, breastfeeding or mother’s education and employment status.
For the immunization comparison, the team used the National Immunization Survey, a project run by the Centers for Disease Control and Prevention since 1994. The NIS conducts telephone surveys and surveys of doctors and other vaccination providers to collect data on children between 19 and 35 months of age. The survey reports national rates of compliance with federal guidelines for vaccination against diseases such as polio, measles, pertussis and tetanus.
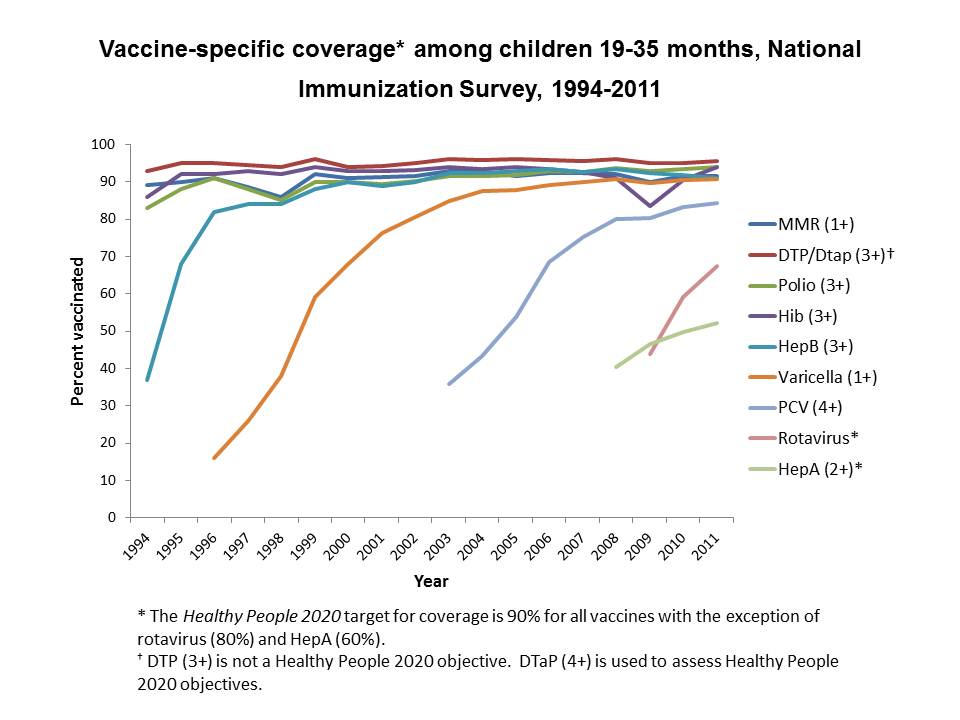
The team compared the vaccination rates in children of mothers enrolled in NFP to the children of mothers in the overall NIS dataset. After running propensity score matching with the NIS, they could also compare how NFP children did to closely-matched children – those whose mothers looked likely to be enrolled in NFP, but were not. The data revealed a positive effect of NFP on immunization rates compared to the other two groups.
“To be honest, I’m still shocked about the results,” Walsh said. “There are other studies that suggest that there’s little to no effect on immunization rates of these particular programs.”
That lack of an effect in prior studies was due more to high rates of immunization in the general public rather than a failing of the NFP program – if the immunization rate in the general population was already high, there wasn’t much room for improvement.
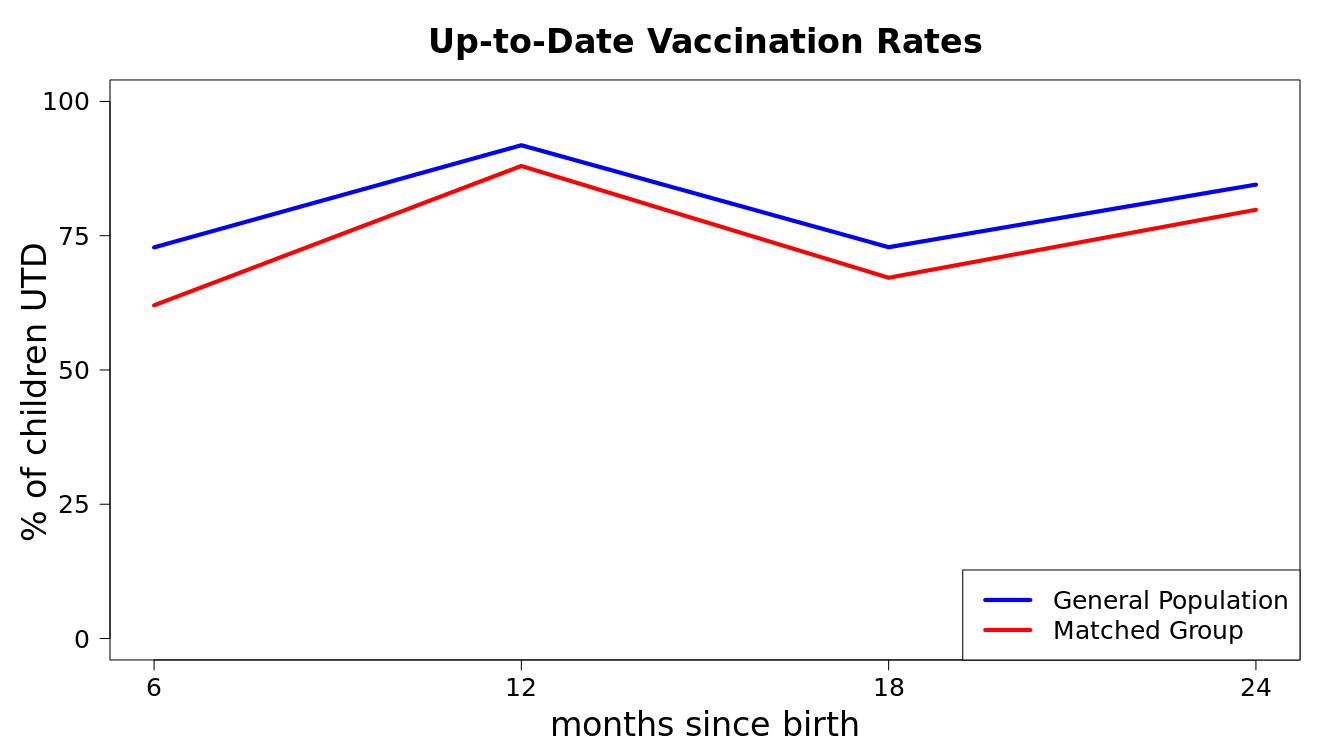
But in the fellows’ analysis, the “matched group” with similar characteristics to NFP mothers showed lower immunization rates than the general population, potentially offering more room for improvement on this outcome.
Still, this analysis remains preliminary, and the fellows want to do more digging into the nature of the datasets from the NFP and other sources. In one fortuitous event, a researcher working with the National Immunization Survey attended a recent Data Science Chicago Meetup where the NFP team presented their project
“It’s places like that where we need expert opinion and expert help to contribute,” Walsh said. “Statistics alone can’t do it.”
Beyond the Outcomes
The fellows on the NFP project hope to do more than just conduct a one-time analysis of the program’s impact. At the end of the summer, they hope to give NFP the methods to continue to evaluate outcomes as more data is collected, or to conduct more focused studies on different regions of the country. The team’s github repository [link] for developing national data sets for comparison will also be open to any other home visitation program that wants to take similar steps to demonstrate their effectiveness.
In addition, the team is working on some more ambitious goals, such as a model that predicts how likely a mother is to complete the full duration of the NFP program through the first two years of their child’s life. Some characteristics may identify mothers at higher risk of dropping out early due to a number of different factors.
The idea came from the team’s visit with the DuPage County chapter of the NFP in June, where they had the opportunity to ask nurses about their experiences administering the program. When asked about mothers who leave the program early, the nurses said they often did not know the reason, or could not have predicted who would stay and who would disappear. The fellows wonder if the data could suggest subtle patterns that were hidden at the individual level.

More broadly, the experience of visiting with the NFP nurses has stuck with the fellows as a reminder that there is a complexity hidden behind the national NFP data they are using for their analyses.
“It was important to get a reminder that there is not a universal NFP experience or client,” Rowe said. “Frankly, that makes our job much harder, because when we work with aggregated data sets we often have to assume that individuals and programs are the same except in obvious, measurable ways. They obviously aren’t, and we’re going to have to deal with that uncertainty. It’s yet another reason to regularly reflect on the work we’re doing and to challenge our assumptions and conclusions.”