As a young, rapidly-growing, and broad field, data science has a language problem. A self-described data scientist may prefer to program in Python, R, or Stata. They use cloud computing resources, relational databases, or MapReduce. For visualizations, they may be experienced in Tableau, the ggplot2 library, or GIS mapping software. Data scientists may be skilled in machine learning, natural language processing, or network analysis. But it’s rare to find one person who is an expert in all of these tools, never mind the new languages, software, libraries, and resources launched nearly every day.
One way Data Science for Social Good addresses this Tower of Babel effect is to form teams that complement each fellow’s experience across these methods and tools. But another way to get everyone on the same, er, screen is to conduct an intensive, two-day bootcamp in the first week, flying at 30,000 feet through some of the most important tools fellows and mentors will use in their summer projects.
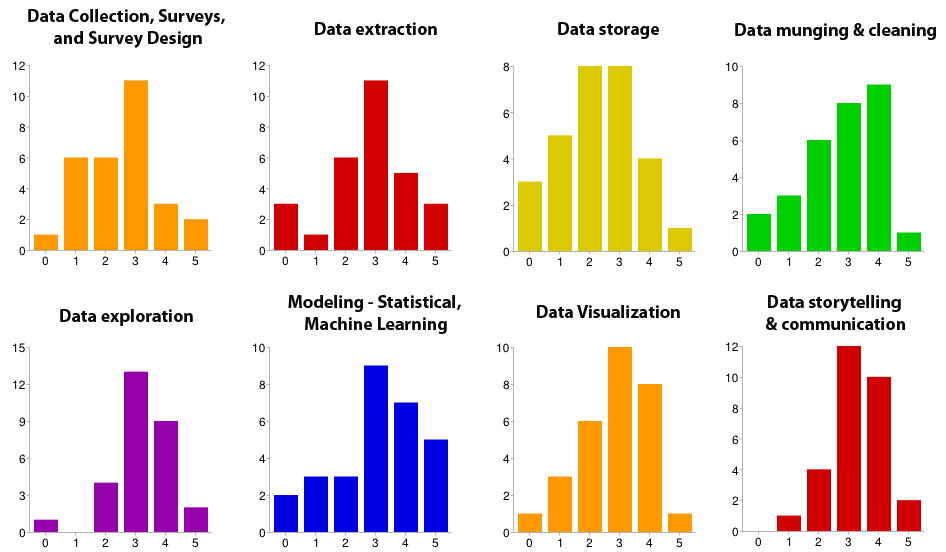
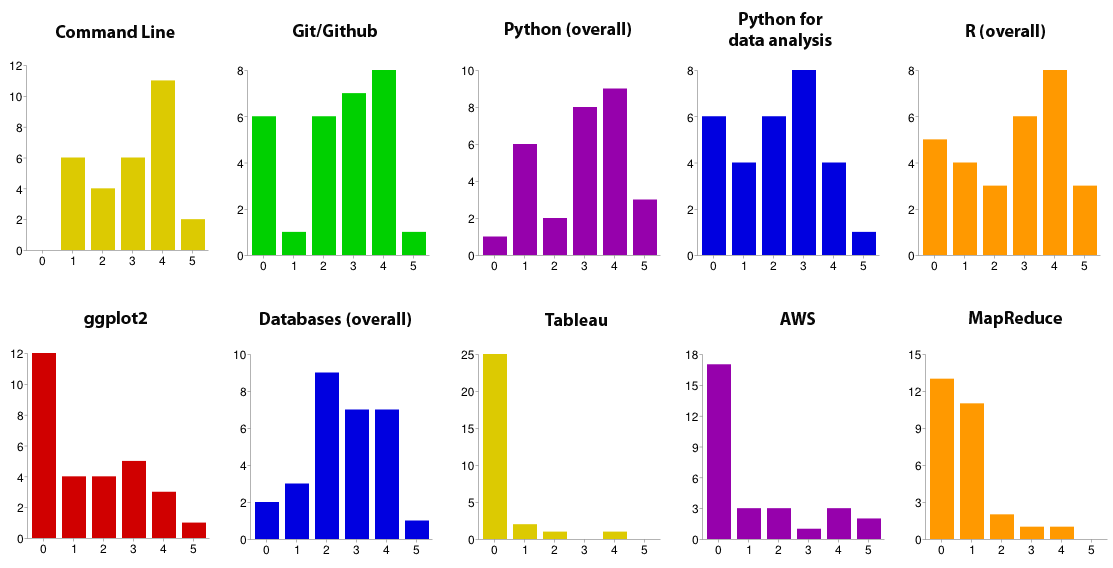
A survey given before the start of the bootcamp illustrated the diversity of fellows’ experience with different tools and methods. Fellows were asked to rate themselves from 0 (no experience) to 5 (highly proficient) on different skills, tools, and methods. Note: only 30 of 48 fellows responded to this impromptu survey. You can view similar data from last year’s fellowship in this blog post.
Skills
Tools
Methods
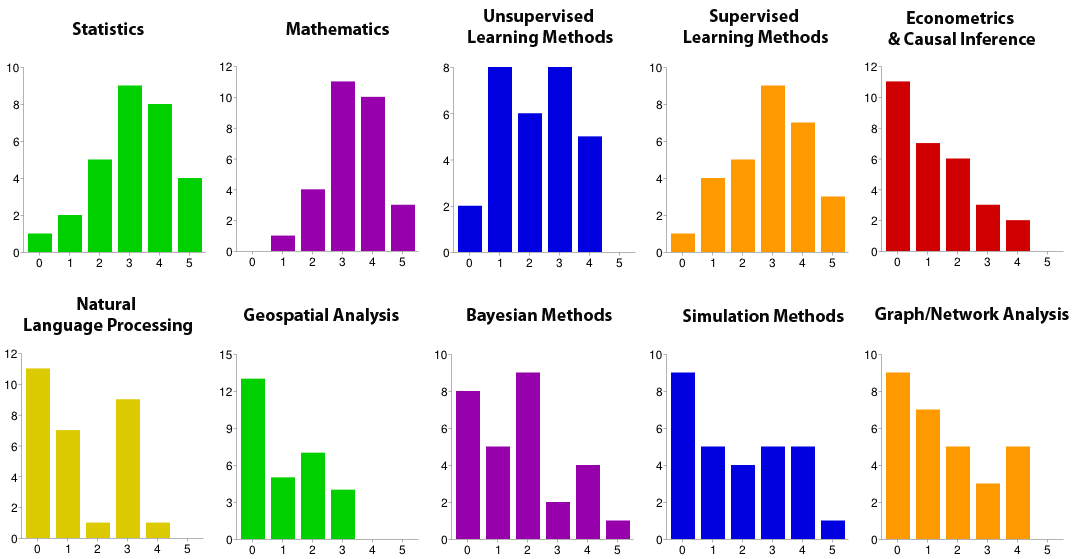
It would be impossible to move everyone into the 5s on the above graphs in two days, or even twelve weeks. So DSSG mentors leading the bootcamp sessions at least concentrated on moving the 0s and 1s to the right. In his Python session, Matt Gee (pictured at top) showed students how to use iPython notebooks and the numpy, scipy, and pandas packages for data analysis. Joe Walsh explained the different situations where R is better than Python (and vice versa), and demonstrated the visualization package ggplot2. DSSG director Rayid Ghani tackled relational databases and the SQL languages, showed students how to obtain additional, cloud-based computing power from Amazon Web Services, and introduced the group to the visualization software Tableau.

On the afternoon of the second day, the fellows were exposed to a different language entirely — the language of how data is used inside non-profit organizations. Representatives from After School Matters, Chicago Public Radio, Elevate Energy, and YMCA of Metropolitan Chicago explained how their organizations collect and use data, from evaluating the success of programs to finding new payment options for fundraising to finding opportunities for energy-efficient retrofitting in apartment buildings.
The fellows peppered the visitors with questions: what is the most interesting data you’ve collected? What problems do you want to solve? What are the challenges you face from inside your organization? Most answered the last question with a plea for more data scientists, skilled in the technical tools and methods described above, to enter the non-profit workforce and help extract the most meaning from their data.
“There are lots of non-profits who want people like you, so keep that in mind,” said Jill Young of After-School Matters.
