
Last week, DSSG fellow Peter Landwehr went to one of Enroll America’s tabling events at Richton Park, IL, and watched how it went. The event was a standard Enroll America information session, with a volunteer sitting behind a table at a library, handing out information to passersby, and getting their contact information in turn. Here is one of the “commit cards” that the woman behind the table was handing out:

The bullet points listed on this form—that financial help is available for many, that you can get free help, and that you might be eligible for a special enrollment period because of extenuating life circumstance—are the cornerstones of Enroll America’s message. Enroll is a national, nonpartisan not-for-profit, whose mission is to get everyone in the country enrolled in health insurance on the federal and state exchanges mandated by the Affordable Care Act (ACA). Last year, during the first open enrollment period, their organization and other efforts helped over half of the previously uninsured population in the United States find subsidized insurance opportunities thanks to the ACA.
The second open enrollment period begins this November, and the DSSG team (Peter Landwehr, Diana Palsetia, James Savage, Sam Zhang and mentor Tom Plagge), are working with Enroll America on new strategies to reach the remaining uninsured. Enroll’s GetCoveredAmerica campaign played no small part in getting those first eight million people covered, and we’re excited to apply the troves of data collected from that first campaign to make the second even more successful.
Warm Calls
As explained to us by David Elin, Enroll’s state director for Illinois, they believe that the best way to get people to register for healthcare is the personal touch. They want to reach out to individuals who express an interest in buying insurance on the exchange and do everything they can to make sure that that process goes as smoothly as possible.
During the last enrollment period, they scored individuals based on their likelihood of already being insured. This helped them decide where they should locate their campaigns and where they should try making phone calls. The members of Enroll to whom we’ve spoken have termed this “warm” calling because of their ability to estimate peoples’ needs for insurance.
Now Enroll wants to try and make its calls even warmer by approximating the probability that being contacted by Enroll will encourage an individual to actually sign up for insurance. We’ve called this variable “persuadability.” We’re creating this variable by building a model for the people contacted by Enroll during its outreach cycle, and another model over the people who weren’t, and predicting whether they ultimately bought insurance. Then, by feeding each individual through the opposite model, we can see which individuals were likely to have acted differently in the counterfactual world.
Expanding the Search
While Enroll’s data gives us some important advantages, it suffers from one critical weakness: it comes from people who we know are interested in getting insurance. The goal of the second enrollment period is to find individuals who are out of the way, who don’t know that the ACA exists, or who have no idea that it applies to them.
Unlike the first year of the GetCoveredAmerica campaign, we also have access to a treasure trove of information from the last enrollment period. There are over three million contact points between Enroll America and consumers, as well as a dozen messaging studies and randomized, controlled experiments.
For example, proportionally fewer uninsured Latinos enrolled in the first period than the rest of the U.S. population. According to Enroll America research, this population feels alienated when the message isn’t presented in the correct language. So the second major objective of our project is to create a model to figure out which families prefer to be contacted in Spanish–and not all Latino families do.
To start looking for effective methods for reaching this population, we built a correlation matrix of subsample of features from Enroll America’s Latino survey data. Listed across the top and the left-hand side are features collected from the survey and other data sources, such as whether the respondent prefers Spanish or English, whether they’re a homeowner, registered to vote, and household income. Each box then represents how highly two of these features correlate with, darker blue indicating a positive correlation and darker red indicating a negative correlation.
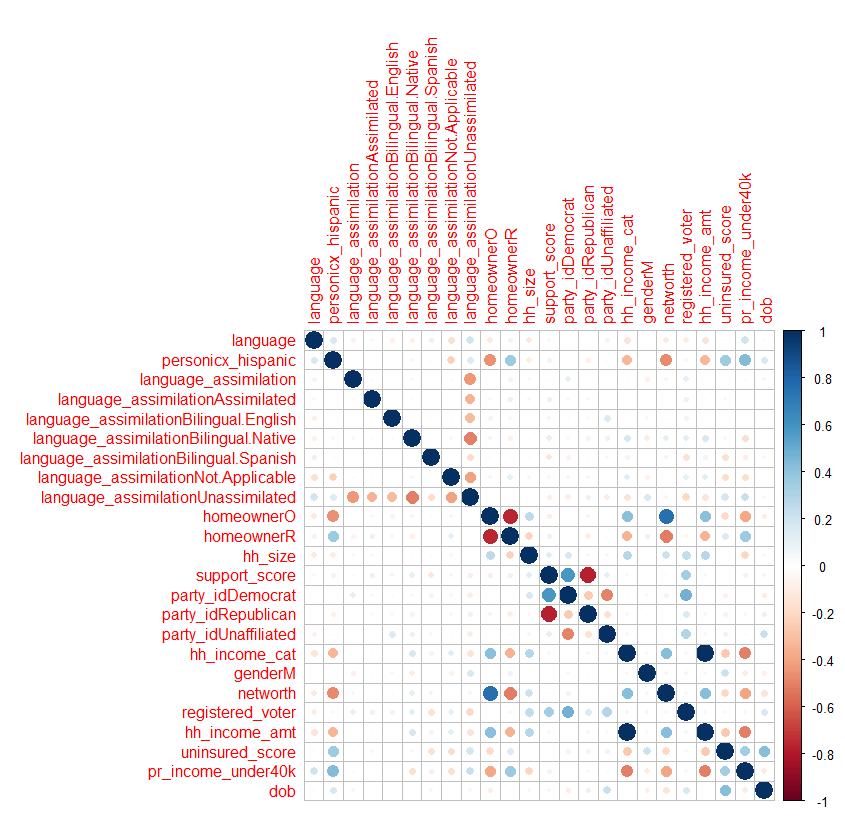
Looking at this graphic, we realized a person’s preferred language was not predicted strongly by any individual feature in the data set. We then explored other methods, such as a LASSO regression, to find combinations of features that have more predictive power for selecting the right language for outreach.
This is just one example of the types of exploratory data analysis we’ve been doing to understand our data on a high level. We are also looking at whether people are eligible for subsidies under the Affordable Care Act, and for the most promising geographic locations for Enroll to hold events like the one Peter attended in Richton Park.
At this point, we’re well into the initial work of data science: reading through database tables, coming up with hypotheses, and building prototype models. We’ve got a great project, some excellent material to work with, and a positive outlook.