
In the Chicago Public Schools system, each school’s budget depends on how many students enroll there. Unfortunately, it can be difficult to predict how many students will enroll in a given year, and inaccurate predictions can result in last-minute money shuffles, staff changes, and wasted educational time. Because budget allocations are made in the spring, long before students start in September, early and accurate predictions of student enrollment are crucial.
This summer, our team — Vanessa Ko, Andrew Landgraf, Tracy Schifeling, Zhou Ye, and mentor Joe Walsh — are working with Chicago Public Schools to better predict school enrollments. We aim to create a frequently-updating model that incorporates not only historical enrollments but also measures of neighborhood health and school and student performance. These other factors are especially relevant in the important grade 8 to 9 transition, because where a student chooses to go to high school depends on more than just geographic proximity.
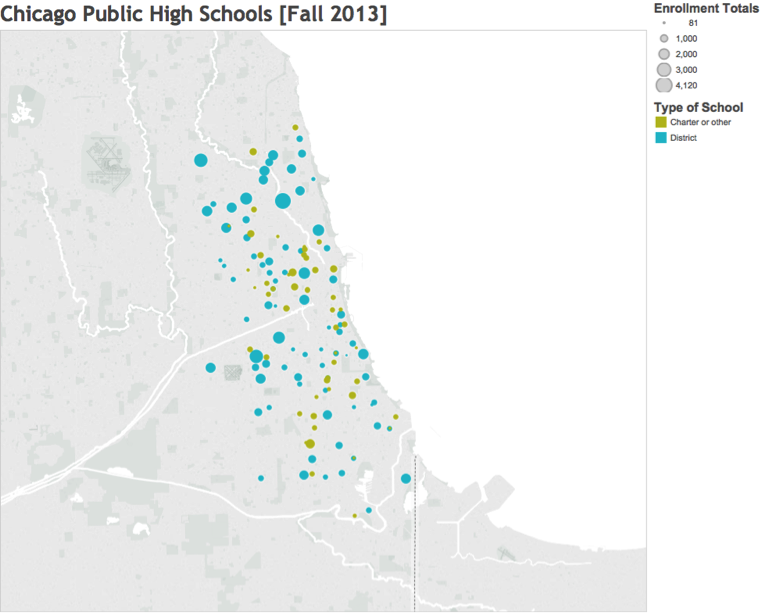
In the plot below, we map the public high schools using public data (from the CPS website and the City of Chicago data portal) using the data visualization tool Tableau. The size of each dot corresponds to the enrollment at each school on the 20th day of the school year, and the color distinguishes district schools and other types of schools. From this plot we learn that the district schools tend to be larger than the other types of schools. We also learn that there are a number of large high schools in the northern part of the city. Our team has spent many hours exploring data visualizations such as the plot below to get familiar with the data and to start brainstorming how to solve our problem.
Starting to Solve the Problem
Working with data in the real world differs from working with data in the classroom, as all four team members quickly learned. In grad school, we mainly focus on developing new methods; at DSSG, our job is apply the appropriate methods to the problem at hand.
CPS stores huge datasets in many formats for different purposes. Once we received access to CPS’s database, it took a lot of time and several meetings with CPS to figure out exactly which data would be helpful for our project.
From our data exploration and meetings with the Demographics team at CPS, we found that CPS has the most difficulty predicting where students go in “entry-level” grades, such as kindergarten, 1st grade, and 9th grade. So we split the problem in three parts: predicting kindergarten and 1st grade enrollments; predicting 9th grade enrollments; and predicting continuing-grade enrollments (grades 1 to 8 and grades 9 to 12).
We have also spent time brainstorming how to incorporate other data sources. For example, Chicago releases years of crime data, which we think can be helpful, but how do we incorporate this into a statistical model about schools? So far we have total crime counts by the high school boundary regions, and we have yet to explore whether this information helps predict enrollment patterns.
One Size Doesn’t Fit All
When CPS predicts 2nd grade enrollment at school ABC, they look at the school’s counts of 1st graders and 2nd graders from the past few years and calculate their best guess of how many 2nd graders there will be next September.
The plot below compares two simple methods of predicting the next year’s enrollment. The red line uses last year’s count from the same grade; for instance, how well the number of second graders in 2012-13 correlates with the number of second graders in 2013-14. The blue line uses the previous year’s count for the preceding grade; for example, how well 1st grade enrollment in 2012-2013 predicts 2nd grade enrollment in 2013-2014.
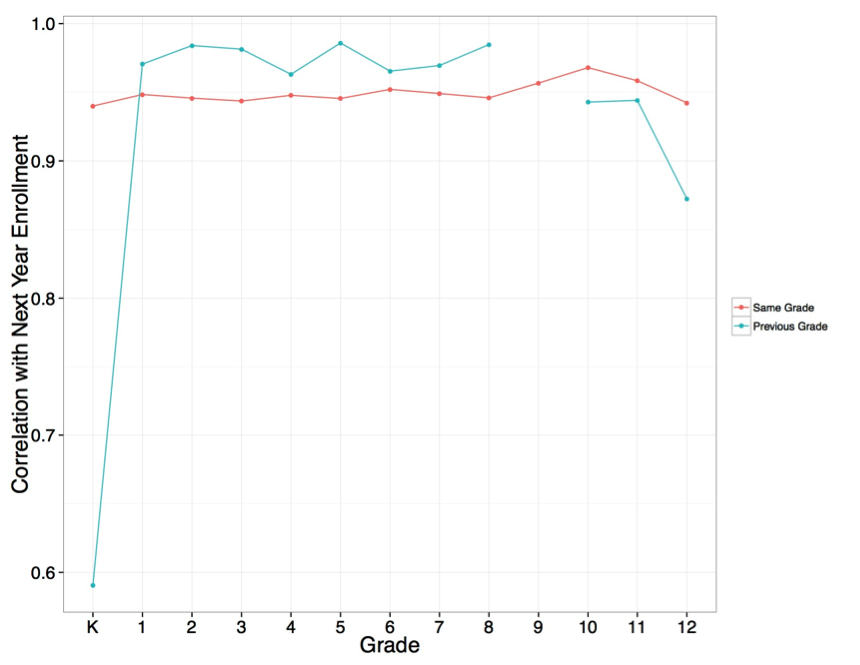
So what does this plot tell us? Different approaches work better for different grades. Next year’s 4th grade enrollment more strongly correlates with this year’s 3rd grade enrollment, but next year’s 11th grade enrollment is more correlated with this year’s 11th grade enrollment. That result demonstrates that predicting enrollment for different grades, never mind different schools, may require different approaches.
Given the difficulty of creating a one-size-fits-all model, we started to think about what aspects of the problem we actually can solve with statistics and machine learning.
Once we started to explore enrollment data from the past few years, we realized that our initial goal of creating an amazing all-encompassing predictive model for 600+ schools was unrealistic. There are some things we just cannot predict. For example, if a school previously offered grades K-3 and then adds grades 4-6, nothing in the historical enrollment data helps us predict this change. There is a lot of context-specific information that dictates school enrollment that cannot be captured in a statistical model.
We have a few thoughts that we will explore this summer. We will work on creating a model that shows how certain events, such as the addition of a new high school or the closing of an old school, influences enrollment patterns in nearby high schools.
We will also try to improve the accuracy of predictions at some of the largest high schools and focus on incorporating neighborhood-specific details that might be able to provide a little more accuracy.
Ideally, we will finish our work at DSSG with a school prediction tool-kit, composed of prediction models, each aimed at a different problem, that we can present to Chicago Public Schools.