An essential step for nearly every data science project is to build a statistical model, an algorithm or analysis that converts raw data into predictions, classifications, or other insights. At DSSG, whether teams are focused on identifying struggling high school students, teasing air conditioner usage out of meter data, or spotting corrupt bidding practices, an important goal of the summer will be to construct a model that can be used to predict or describe certain behaviors.
But while some types of analytics are largely concerned with the predictive accuracy of their models, working with nonprofits and government agencies creates additional expectations, a higher bar for these models to reach. As repeatedly stressed during a special edition of the DSSG weekly updates on Tuesday, models built for social good need to be connected to predictive (if that is the goal of the project), interpretable, actionable, and practical solutions for those who will eventually deploy this into real practice.
“
The special modeling-focused session was scheduled by DSSG director Rayid Ghani as an important mid-summer checkpoint on the progress of this summer’s projects. A model is not necessarily the crucial part of the fellowship, he said. Far more important is building a process pipeline, from problem understanding to raw data to data understanding to feature construction to model building to model output, that teams can then evaluate, interpret, fine-tune, and improve over the final weeks of the program.
Finding The Right Fit
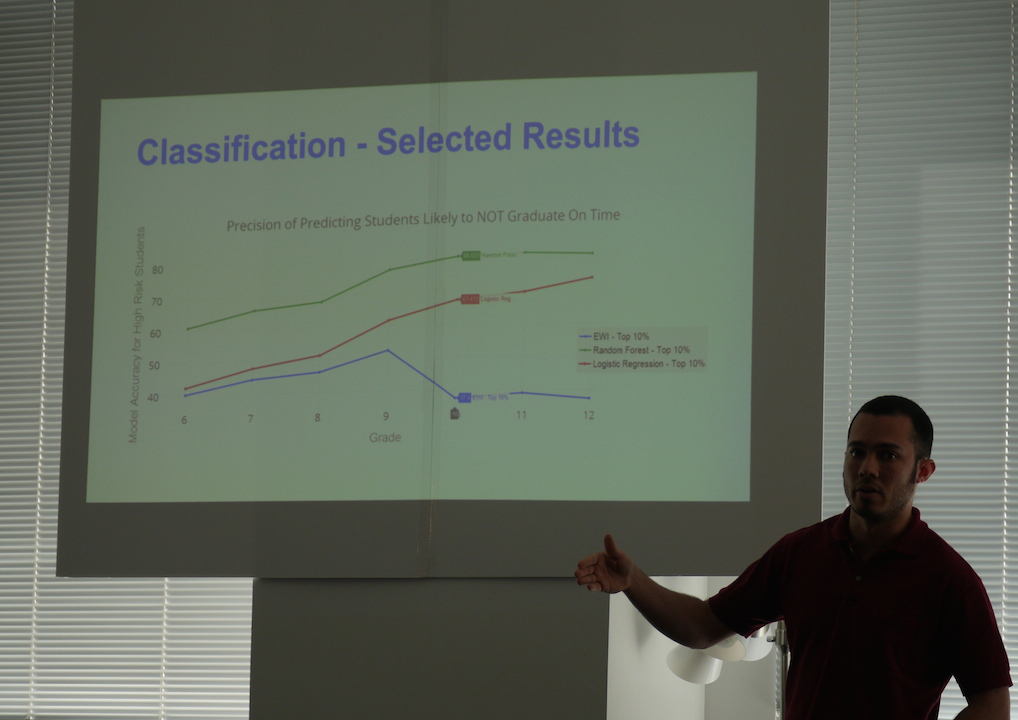
Over the 13 presentations, a wide range of modeling strategies were discussed: logistic regression, k-means clustering, random forests, hidden Markov models, neural networks. Teams also sought different types of output from their models, and different measures of success. Some projects sought to classify entities, such as at-risk students, or likely lead-contaminated houses, with high precision.
Others looked to identify the most important features within the data that predicted whether someone would stay enrolled in a maternal and early childhood health program or a homelessness intervention. Still others tried to predict a quantity, such as school enrollment, or combine data to define new characteristics such as “contactability” or “responsiveness” that can be used to optimize a partner’s outreach and interventions.
In some cases, fellows found that their original model performed well, but didn’t produce the kind of output that their partners were would find actionable. The City of Memphis team, for example, originally set out to identify individual blighted properties, said Ben Green. But conversations with the partners led them to instead build a model that identified blocks with a high percentage of blighted parcels — a higher level where city workers could more easily follow up to identify problems and potential interventions in struggling neighborhoods.
Similarly, the World Bank Group team looked for corruption at the level of individual companies bidding for contracts, within different sectors of projects, and on the scale of entire countries. But their World Bank collaborators, who determine where investigation resources are targeted, nudged them towards focusing on suspicious industries or companies instead of countries where corruption is likely to occur, for both practical and political reasons.
“We learned that the classifier might not be so valuable even if it performs really well,” said fellow Misha Teplitskiy. “The features we’re working with on the country level aren’t very actionable, and predicting on companies is more appropriate.”
No Black Boxes Allowed

Another common theme was moving from models built on unsupervised statistical methods agnostic about the realities of the world to more relevant insights that partner organizations can take actions on. Natural language processing methods used by the Skills for Chicagoland’s Future team to match job seekers’ resumes with employers’ job postings provides an important first step for wading through millions of documents, but may make matches that wouldn’t make sense to a human observer.
Teams performing feature extraction tasks that identify the most important factors for predicting an outcome such as maternal mortality or program retention may find unexpected results, prompting further discussion with their project partners about whether those features are useful for real-world interventions or further exploration. In all such cases, Ghani said that it’s important to remember that the model should only be used as an initial step in the overall process guide, and should not be used without digging deeper into what it’s learning and what that means about the individuals or entities in the data.
“Models typically built on observational data only give hypotheses around whether a particular feature is important or is a leading indicator, certainly not giving any evidence for a causal relationship,” Ghani said. “These should drive your conversations with partners; if these four features were predictive, let’s now do an experiment to figure out if there is a causal relationship there or not.”