“We believe that ending homelessness is possible and that, in Chicago, everyone should have a home.” – Chicago’s Plan 2.0: A Home for Everyone

Problem definition
On a bitterly cold night in January 2013, Chicago counted more than 6,000 people without a home. While so many Chicagoans are without one of the most basic human needs, the Chicago Alliance to End Homelessness forms the backbone of Chicago’s collaboration involving roughly 200 organizations to ensure that every Chicagoan has a place to call home. And this summer, the Chicago Alliance asked us to develop a comprehensive historical analysis of their data to inform strategies and planning for coming months and years.
With so many organizations providing different services around the city, all in an ecosystem called the Continuum of Care (CoC), the Chicago Alliance wants to know: what kinds of services work best, and what kinds of services work well for what kinds of people? At the beginning of the summer, after a couple of meetings with the Chicago Alliance, we outlined a three-pronged approach to this question.
Most importantly, we are evaluating the effectiveness of different program models in order to inform CoC planning activities. We are not looking at individual service providers; rather, we are considering trends across the different kinds of programs they provide. Primarily, we are investigating different housing program types, including permanent supportive housing, interim and transitional housing, emergency shelter, and other strategies.
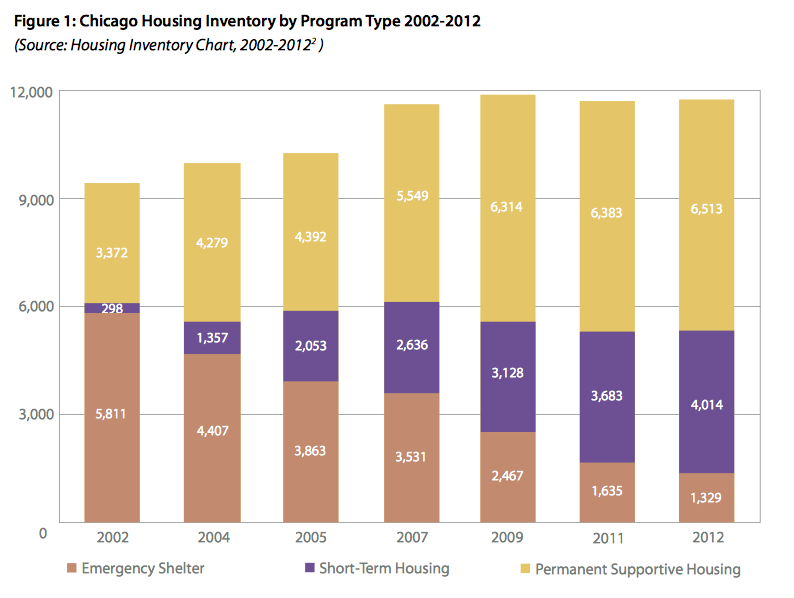
From Chicago’s Plan 2.0: A Home For Everyone
Moving more in-depth, we hope to provide accessible, intuitive insight into what paths people take through the Continuum of Care. What kinds of people are likely to succeed in what kinds of programs, where do people come from, and where do people go after they finish a program? Furthermore, many people enter and reenter into housing programs, and our partner wants to know what patterns exist and how people move through the system over time.
Finally, to inform the other two objectives, we are modeling how well a particular intervention might work for a given individual or population based on demographic and housing barrier data, enabling the targeting of the most effective supportive housing interventions for households. Unlike some other projects in the Fellowship, this modeling is not a primary focus. Nonetheless, modeling will support our other objectives.
Lived experiences of homelessness
We are particularly excited to be working with the Chicago Alliance and the institutions they support because they work so directly with some of Chicago’s most vulnerable, and because they incorporate the people whom they serve into their leadership. The Lived Experience Commission of the Chicago Alliance includes individuals who were formerly or currently at risk of homelessness, and it provides a strong and experienced voice in the mission to prevent and end homelessness.
At the beginning of the summer, our team spent a morning at a city-wide meeting hosted by the Chicago Alliance and were privileged enough to hear from and talk with the Lived Experience Commission and others personally affected by our work. The Chicago Alliance’s close work with their constituency gives us confidence that our work will be used to lift up and complement the voices in this struggle that matter most: those of people with lived experience of homelessness.
Our team, however, is mostly new to the space of homelessness services. Chris Bopp has worked for the AIDS Foundation of Chicago in the past, but the rest of us have no background working in the sector, so we wanted to make sure we had as clear a sense as possible of the organizations and ecosystem with which we’d be working.
In the first few weeks, we took plenty of time to visit and talk with people who had their boots on the ground. We talked with case workers, managers, and data managers at an emergency and short-term housing provider and at a larger organization that provides other services like rapid rehousing and homelessness prevention services. It was important to us to hear from the people who have direct experience serving homeless Chicagoans and who know this work inside and out, and the commentary we got from them and the insights they brought to the table have been invaluable in informing our work so far.
For example, we expect to see that family size and composition are important factors in stable housing and income, because families with small children often have trouble getting childcare or other needed services. And, because there is not enough affordable housing in Chicago, people often go into housing programs that are available at the time, rather than housing programs that will address their needs best. We expect that these insights will lead us down fruitful paths in the data, and will allow us to focus on important factors.
The data
The Chicago Alliance has given us anonymized, individual-level data from the last 15 or so years. All of the organizations in the Chicago Continuum of Care keep track of cases in the Homeless Information Management System, or HMIS. HMIS has a record for each service any person received with information about the person, including some demographic data.
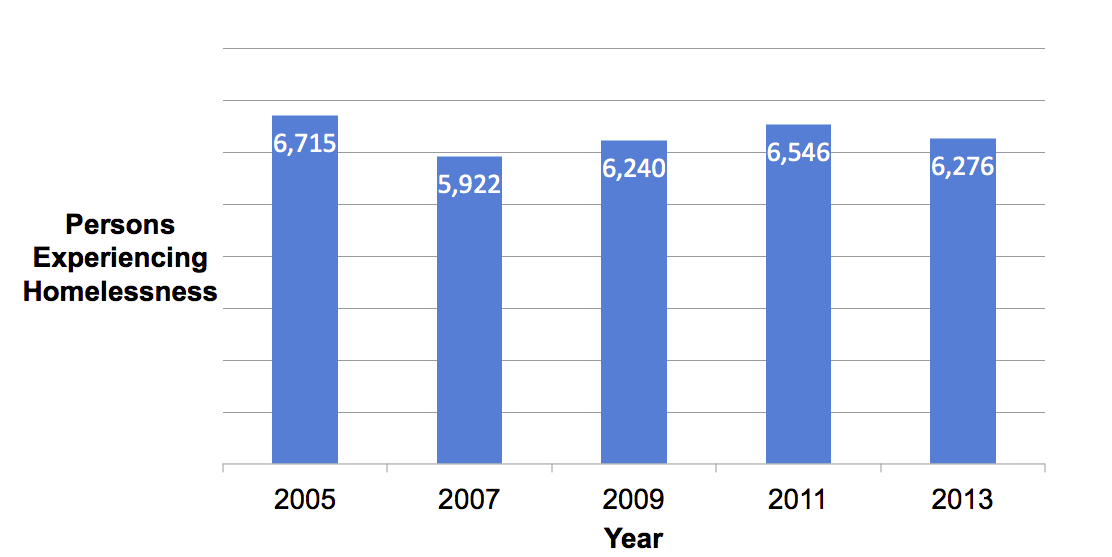
Homeless population in Chicago from point in time counts, 2005 – 2013
So, for every time anyone has recieved a service, there’s a corresponding entry in HMIS…at least, in theory. The data going back a decade and a half has lots of missing, and often contradictory, information. However, in September of 2012, HMIS management was taken over by the Chicago Alliance, and data quality improved dramatically. We decided with our partner to restrict our analysis to the last two years. But we are still incorporating legacy data in order to enrich the more current data by looking at, for example, the first record of a client interacting with the Continuum of Care.
What do you do with a pile of data?
When we started this summer, I have to admit that we didn’t really know where we were headed. All of our team members were bringing different and important skills to the table, but none of us had ever worked in data science before. What do you do with several dozen columns and millions of rows of data?
We looked through the columns, started to get a sense for what the quality of the information was, and of what it meant in context. At first glance, a column might have seemed straightforward, but when we realized it contained information that didn’t make sense, (and it almost always did,) we had to ask why. The complexities of the answers ranged from simple, (“It’s just a default value”) to very complex, (“This column often conflicts with this other one, and you’ll have to look at the other rows with similar information to figure out which one is right”).
A few weeks in, we had spent countless hours going through every column of every table, trying to get a complete picture of what was going on and what we needed to do to get it clean. Looking back, we spent a lot of time on data we would eventually abandon, either because it was too sparse to use, or because we simply didn’t have time. It would have been far more prudent to pick just one column—just one!—to use as a predictor, pick just one column—just one!—to use as a target (what we would try to predict, in this case, housing stability), and run an analysis on it. Even that takes substantial time, but it would have gotten us running earlier, which, in a 12-week project, is extremely important.
So, we definitely made some mistakes along the way, but ten weeks later, I feel pretty confident that if someone handed me a new dataset tomorrow, I’d know a lot more about what to do—and not do—with it.
Initial models & visualizations
After getting familiar with the space of preventing and ending homelessness, plowing through the data, we started grilling our partner on definitions of terms. Namely, we wanted to know, “What is housing stability, and how can we judge it from the data?” It took a couple of conversations to get clarity on that, but we settled on a definition we’re all happy with. For any short-term program, housing stability depends on if you exit the program to a ‘permanent’ destination; for a permanent program, housing stability depends on exit destination as well, but also on how long you were in the program.
Our initial model for housing stability, a random forest, had mediocre performance. We only used a few straightforward features, like age, type of program, and prior living situation, so we didn’t expect it to work terribly well. At least we could say confidently, though, that—at that moment—we didn’t have enough features to accurately predict or say much. That meant digging back into the data and generating more complex features, such as family size, income at entry, and disabilities. These all required some detailed cleaning and combining of different datasets, but we expect they will be more predictive, based off of our conversations with our partner and case managers around Chicago.
We got a chance to build some initial visualizations for our partner, too. One of the key questions they had came from a report done last year, with diagrams like these:
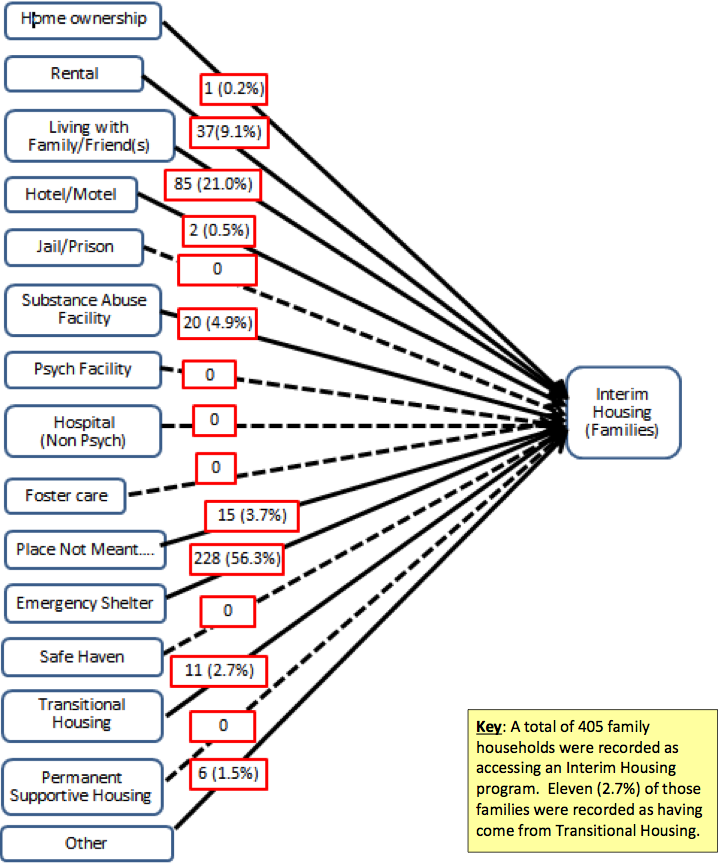
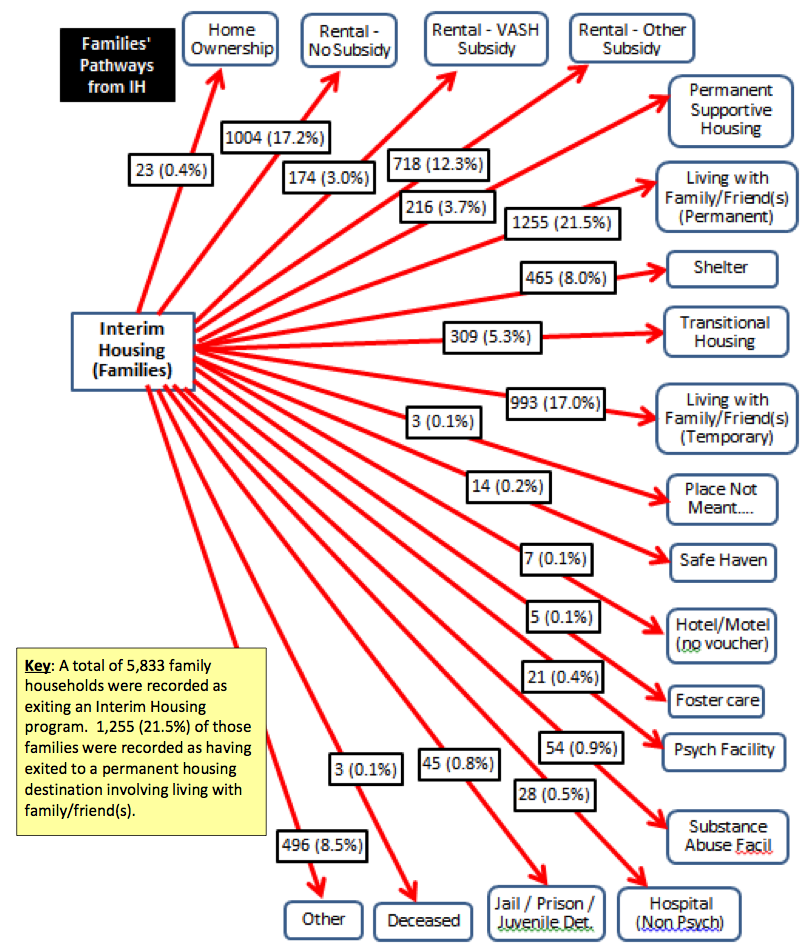
These diagrams show what percentages of people entering and exiting different programs were coming from and going to different places. However, they don’t show, of the people exiting to a particular place, how many of them were entering from a particular situation. We don’t know if most people are exiting to the same place they came from:

Or if they are exiting to different places:
They were also just hard to read, because there were no visual cues, only numbers, to indicate common paths.
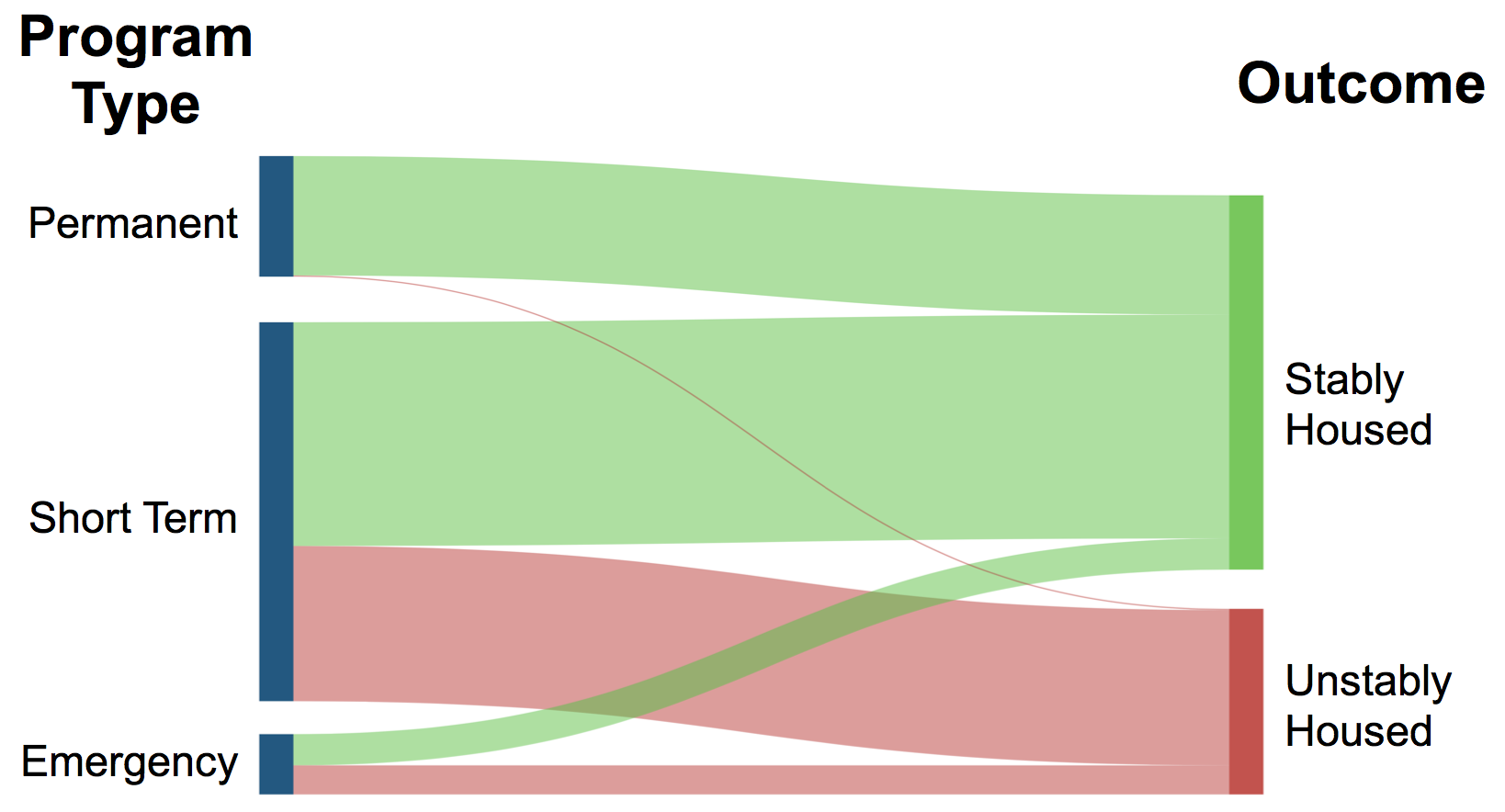
After spending an afternoon discussing what visualizations might be appropriate for this, we settled on building Sankey diagrams. These diagrams are great for showing flows through a network, which is roughly what we’re doing. We’ll also be generating crosstabs with the same information, but Sankeys are particularly easy to understand. Below, you can see how people in different housing program types end up stably or unstably housed. People in permanent housing programs have a very high rate of housing stability, whereas people in short-term housing programs have a much lower rate of housing stability:
In the coming weeks, we’ll be using the models we’re generating to inform what kinds of predictors we should be particularly concerned about in this system. Does age matter, or is it really prior living situation that’s more important? Or, maybe it’s a combination of the two with other factors as well. In the coming weeks, we’ll be generating smarter visualizations informed by our model, and we hope to have more important findings.
Even now, though, we’ve confirmed with data some important planning assumptions. For years, it’s been thought that permanent supportive housing keeps people more stably housed, and now we can intuitively see that in the diagram above. As the Chicago Alliance moves forward in planning, it can look to our work to confirm or deny assumptions about how homelessness services work in Chicago.