
“The greatness of America lies not in being more enlightened than any other nation, but rather in her ability to repair her faults.” — Alexis de Tocqueville
Why Are Earmarks Still Relevant?
Congressional earmarks are legislative provisions that direct federal funds to specific projects. Even though the House Appropriations committee banned earmarks in appropriations bills in 2010, earmarks continue to stir controversy amongst political scientists and policy makers. Supporters of the ban argue that the moratorium on earmarking has significantly reduced pork-barrel spending in Congress and produced a more transparent appropriations process. On the other hand, their opponents claim that, even at its peak, earmark spending accounted for less than 1% of the entire federal budget. Instead of adding more oversight, critics of the ban suggest that it has increased backroom deal-making while undermining the local appropriations process. The conclusions of this debate thus have profound implications for how the United States Congress should function.
Earmarking still remains contentious because there is a lack of publicly available, longitudinal data on congressional earmarks. Uncovering earmark spending is a time-intensive task for policy analysts and government agencies. The Office of Management and Budget (OMB) only collected data on earmarks for four fiscal years (2005, 2007, 2009, and 2010). Compared to the OMB, transparency groups such as Citizens Against Government Waste (CAGW) have government spending data that dates back to 1991.
Ironically, transparency groups seldom make their data publicly available and lack standardized criteria for designating an appropriation as an earmark. In order to address these issues, our team at the Data Science for Social Good Fellowship, in collaboration with the Harris School of Public Policy, developed an automated system that uses machine-learning methods to identify earmarks in congressional documents. Using this approach, we construct the first publicly available database of earmarks that covers every year back to 1995.
Building the Machine Learning Pipeline
Congressional bills are written in very dense, technical jargon. It’s easy to overlook a substantial number of appropriations buried within hundreds of pages of legalese. Appropriations are so elusive that it’s not only important to analyze the bill, but also to inspect the congressional reports and memos accompanying the bill — nearly 95% of earmarks can be found in such documents. Before using any machine learning methods, we spent the first couple of days reading congressional documents. We soon realized that nearly 85% of appropriations occur in tables.
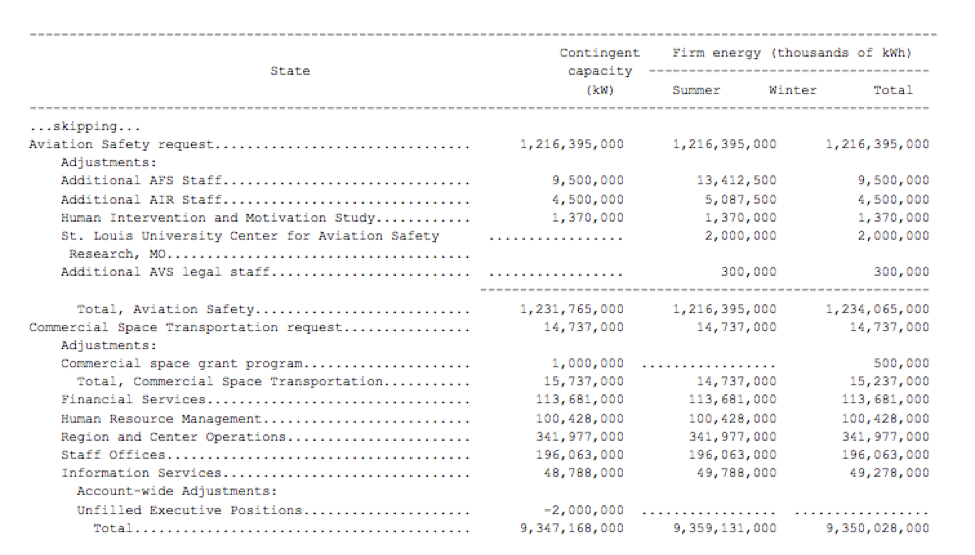
This fact significantly reduced the complexity our problem: we could now focus on extracting budget allocations from tables instead of searching through hundreds of pages of less structured text. For each congressional document, we detected and parsed appropriations tables using a customized table-parsing algorithm. The rows of these budget allocation tables are fed into our model.

While the OMB only collected data for four years, it provided us with the necessary ground truth to label identified budget appropriations as earmarks from congressional documents. We used OMB’s data from 2008, 2009, and 2010 to train our algorithm.

Using OMB’s labels, we applied a supervised learning approach. We generated four broad categories of features from each candidate earmark’s text: geographic features, sponsor features, unigrams, and simple string heuristics.
- Geo Features: presence of a city, presence of a county, and presence of a state
- Sponsor Features: presence of a senator’s last name and presence of a representative’s last name
- Unigrams: n-grams are generally a sequence of n words. A unigram is just a one word sequence. We constructed a vocabulary of unigrams (words) from all of the earmarks in our training set. The vocabulary doesn’t include the most frequent words in the English language and states, cities, counties, and last names of members of Congress. 1 or 0 is encoded if the specific unigram appears in the text of a particular appropriation.
- Simple Heuristic Features: number of tokens, number and percentage of tokens that are numbers, number and percentage of tokens that are words, number and percentage of characters that are of dots, percentage of characters capitalized.
Since rows extracted from appropriations tables are very messy, simple heuristic features serve as strong detectors of malformed rows. Meanwhile, as earmarks are often called ‘federal spending with a zip code attached’, geo features are a powerful indicator of earmarked classification. Unigrams, however, were the most powerful because there are specific words, e.g. ‘university’, ‘transit’, ‘highway’, ‘initiative’, and others alike, that are consistently associated with localized budget appropriations.
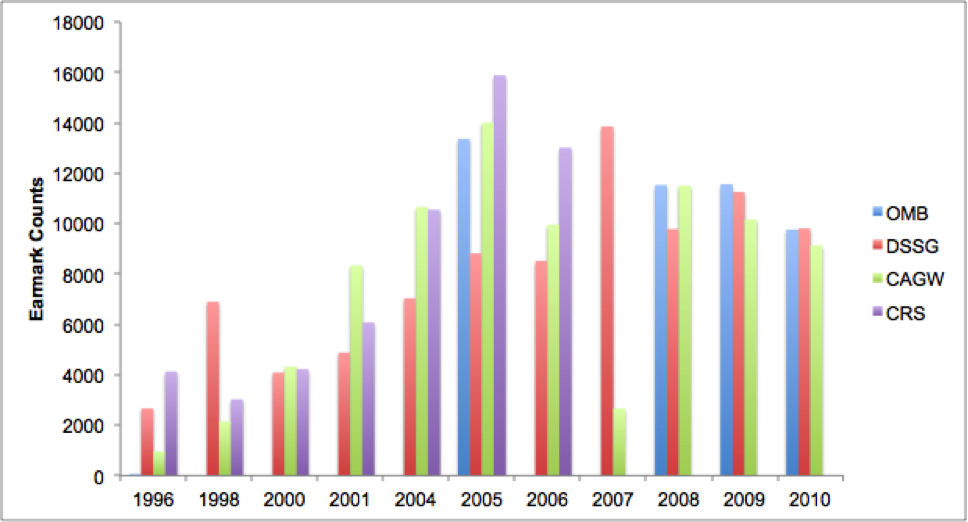
After generating features, we classified if something was an earmark or not using a Support Vector Machine. On the data that we didn’t use for training our algorithm, we were able to discriminate earmarks from non-earmarked appropriations with 95% accuracy. Our algorithm recovers 85.6% of OMB’s database of earmarks. These results are understandable as our pipeline only extracts earmarks from appropriations tables. We also obtained comparable results against CAGW and Congressional Research Service’s (CRS) earmark counts data.
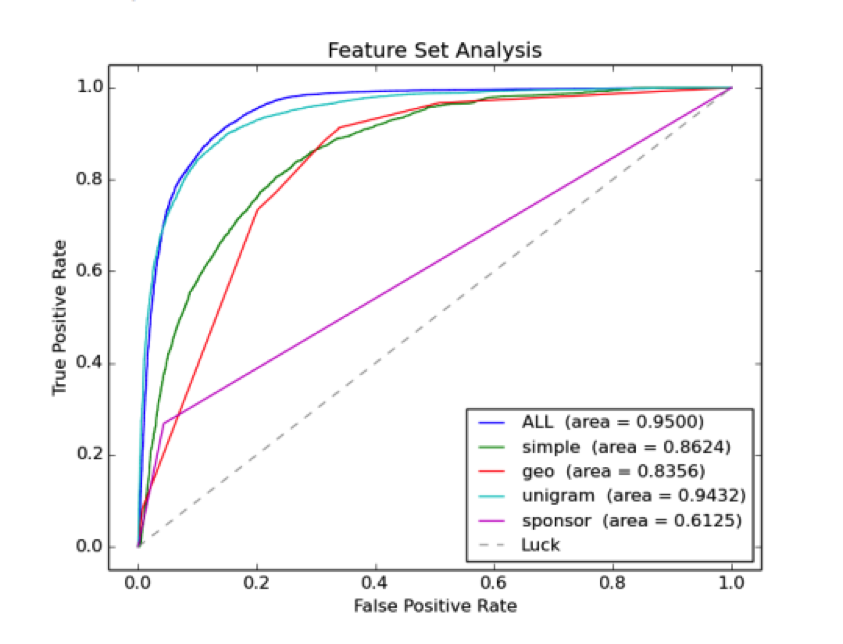
In the past, simply cataloguing one fiscal year’s worth of data necessitated a three month long effort on behalf of the Office of Management and Budget (OMB).Compared to OMB’s manual approach, our machine learning system only takes, on average, 15 minutes to construct a list of earmarks from a given fiscal year’s documents. This allows us to easily generalize our approach to Congresses in the past and future with little human intervention.
Doing Some Data Analysis
Once we compiled a list of candidate earmarks, we used OpenCalais, an off-the-shelf Named Entity Recognizers (NER), to geotag earmarks with locations. We obtained a location for at least 85% of earmarks in our database, with nearly 45% of the earmarks having a precise, district-level association.
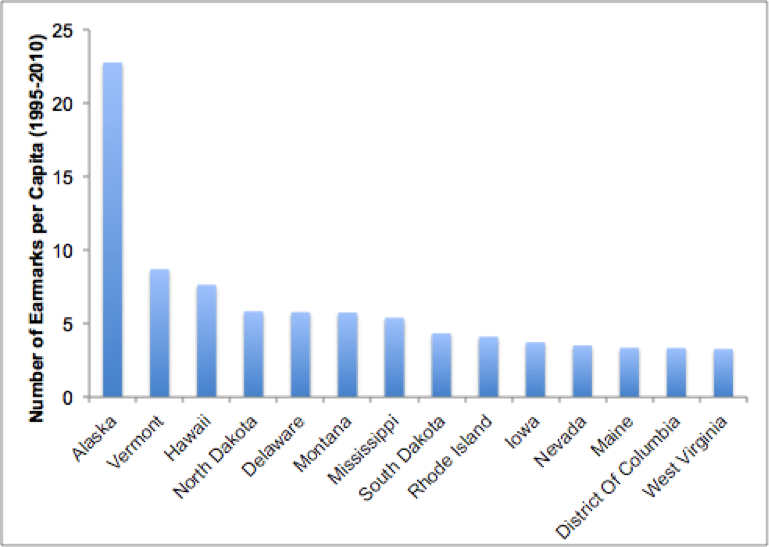
One of the insights we gathered from these geotags is that, from 1995-2010, Alaska received nearly three times as many number of earmarks per capita than the next highest state: Vermont. While the infamous “Bridge to Nowhere” serves as the canonical example of pork-barrel spending, our data set highlights Alaska’s persistent dependence on federal spending during the last two decades.
According to Institute of Social and Economic Research at University of Alaska Anchorage, “when Alaska became a state in 1959, about 80% of jobs in Alaska depended, directly and indirectly, on federal spending. Development of the private economy and a decline in the military presence gradually reduced federal importance to the economy. But starting in the mid-1990s, federal spending in Alaska began growing at a much faster pace, and the economic contribution of federal spending increased.”
Although the federal spending uplifted Alaska’s economy, questions about the causes of the surge and long-term consequences are still open. A potential theory, proposed by Chris Berry and Anthony Fowler at the Harris School of Public Policy, points to the influence of Senator Ted Stevens of Alaska due to his role as the chair of the Senate Appropriations Committee from 1997-2005. Their study, however, only considered two Congresses, 110th and 111th. Using the DSSG data set, it is possible to conduct longitudinal analyses leading to more robust empirical conclusions.
In addition to geotagging classified earmarks, we also built a model to perform topic classification of each earmark. The OMB has labels for the spending committee associated with each earmark. We collapse spending committees related to “Homeland Security,” “Military and Veterans Affairs,” and “Defense” into the category of “Defense and Military Affairs.” Using these categorizations, we assign class labels to each earmark using a multi-class classification model employing Logistic Regression. The average of precision and recall scores for each class was approximately 85%.
From these topic classifications, we note a significant change in the types of appropriations being earmarked. The biggest increase was in the percentage of appropriations related to Labor, Health, and Education. Defense and Military Affairs earmarks mostly increased during the Bush administration. Meanwhile, Energy and Water earmarks decreased by nearly 30% during the same 15-year period.
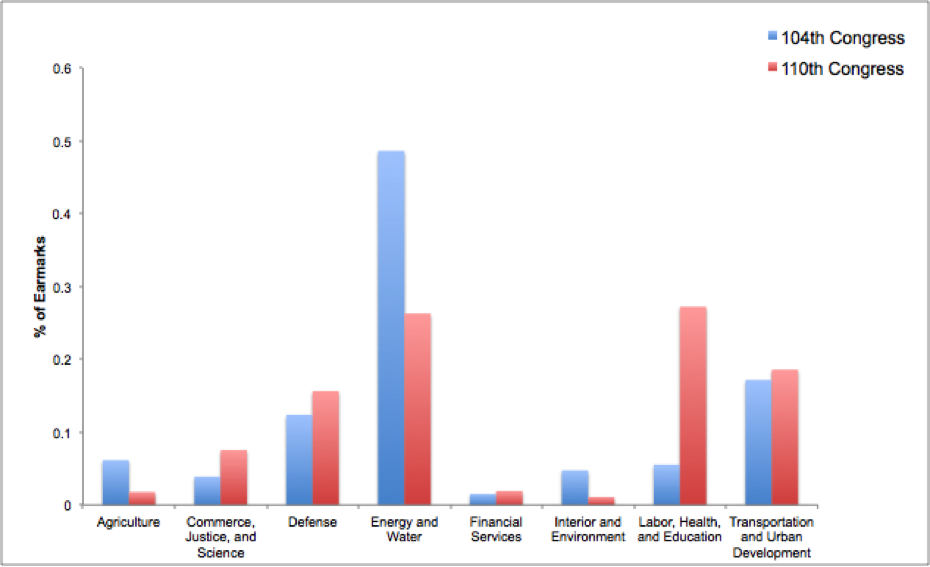
The biggest utility associated with these topic classifications is that they provide more granular insights on how the structure and topics of earmarking have changed over time. They also lend insight into which states and locations have benefited from certain types of earmarked allocations over time and where potential types of earmarking could have been wasteful. We also built an interactive demo upon this information.
Digging Deeper for Democracy
Policymaking based on politics rather than scientific evidence erodes the effectiveness of the American republic. Our summer project highlighted how machine learning techniques can be used to efficiently extract valuable information hidden within thousands of pages of congressional documents. In the next phase of this project, we plan to do the following:
- Improve our table-parsing algorithm to more effectively detect values and sponsors associated with each earmark
- Extend our system by building models to detect earmarks in free text
- Apply our algorithm to congressional documents beyond bills and reports (e.g. congressional resolutions, memos and supplemental appropriations bills)
More generally, bills often go up for a vote before legislators can thoroughly read them. Constituents can’t review legislation pertinent to their livelihood and contact their representatives to raise concerns. This project establishes the foundation for future work on applying data science to effectively mobilize the American public on important issues.