
What’s the problem?
Hundreds of millions of tons of hazardous waste are generated every year. When this waste isn’t handled properly, the results can be disastrous. Chemical spills and explosions pose a serious threat to human health and the environment — in 2014, there were over 20,000 spills in the US, leading to more than 800 deaths and $50 million in property damage. After the fact, it is often impossible to trace or hold accountable the responsible parties.

The Resource Conservation and Recovery Act (RCRA) gives the Environmental Protection Agency (EPA) the authority to track hazardous waste “from cradle to grave” to prevent such accidents. The EPA inspects about 1,500 facilities every year to ensure that their waste generation, transportation, and disposal practices are safe and responsible. However, the prioritization of inspections is heuristic, based on inspector knowledge or government priorities. Inspections are time-intensive and require expertise, and the EPA has limited resources, so we helped them use a data-driven approach to maximize the impact of inspections.
How do we solve it?
This project was a perfect opportunity for the application of data science. First, the EPA had plenty of labeled historic data: the results of every inspection conducted for the past 15 years (the records went back to the 1970s, but the data quality was not reliable before 2000). Each inspection was an observation, meaning we could identify patterns both between facilities and within a given facility — if a facility was inspected twice, and only violated once, we could see what had changed between the two inspections that might explain the different outcomes.
Second, the EPA collects data across a wide variety of regulatory and reporting programs, but until now this information has been siloed. For the first time, the EPA could utilize information from other regulatory and reporting programs to inform RCRA inspections; for example, maybe facilities that violate the Clean Air Act or release dioxins into streams are also more likely to violate RCRA regulations.
Speaking with domain experts at the EPA was invaluable and informed many of our modeling decisions. For example, we learned that facilities that had previously underreported the amount of waste they generated might be more likely to violate in the future. We were able to calculate this feature directly from biennial reporting data and include it as a model input.
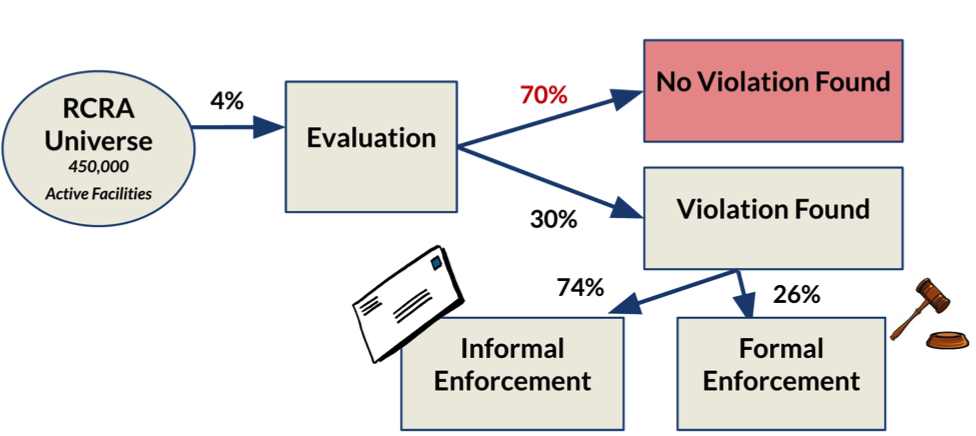
Understanding the inspection process was also critical to identifying our outcome variable. Thirty percent of inspections end up identifying a violation. Of those, about 26% result in a formal enforcement, which could potentially be considered a more “serious” violation. We had two choices: maximize the total number of violations found, or maximize the number of violations found that result in a formal enforcement, thinking that this serves as a proxy for how severe the violation is.
We used the first outcome (violation found or not found), because the average time from the date of inspection to a formal enforcement is about a year and a half, and can be as long as 27 years. Using an outcome variable that is determined at the time of inspection meant we didn’t have inspections that were labeled as not being violators when they really just hadn’t reached that point in the enforcement process.
How do we evaluate the model?
To emulate the way the model will truly be used, we “predict the past” and come up with predictions (violation or no violation) for facilities given what we knew at the time they were inspected. Then we compare our predictions with the true results of the inspections.
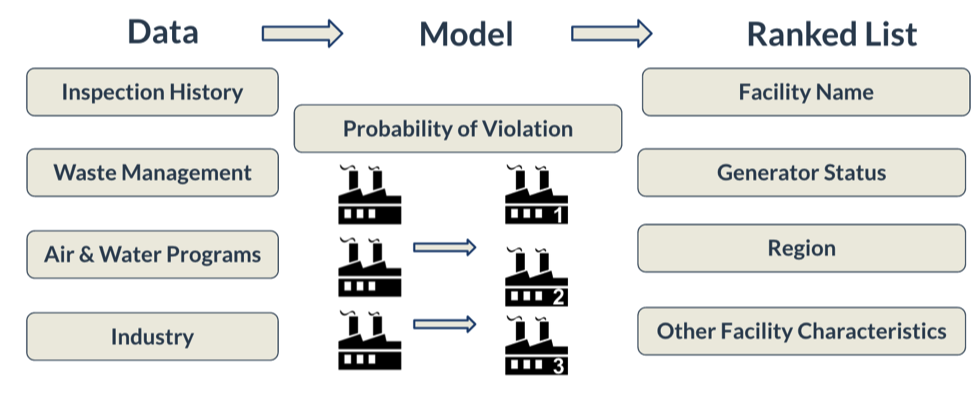
How do we quantify performance? It doesn’t make much sense to look at accuracy over all facilities, since the EPA can only go to 4% of facilities every year. We want to maximize the number of facilities that the EPA visits where they actually find a violation. This means that our metric of interest is precision in the top K%, or how many of the top K% of facilities (ranked by the risk score output by our model) that are actually in violation. We choose K based on the size of the test set we use to evaluate the model. For example, if a given test set contained 30,000 inspections, we would look at the top 5%, or 1500 inspections, because that is representative of the actual number of inspections the EPA would conduct.
How are we doing?
The plot below shows our results on the actual inspections from 2013. As we would hope, we can see that the proportion of violations is highest among the facilities that had the highest risk score, and decreases as the risk score decreases.
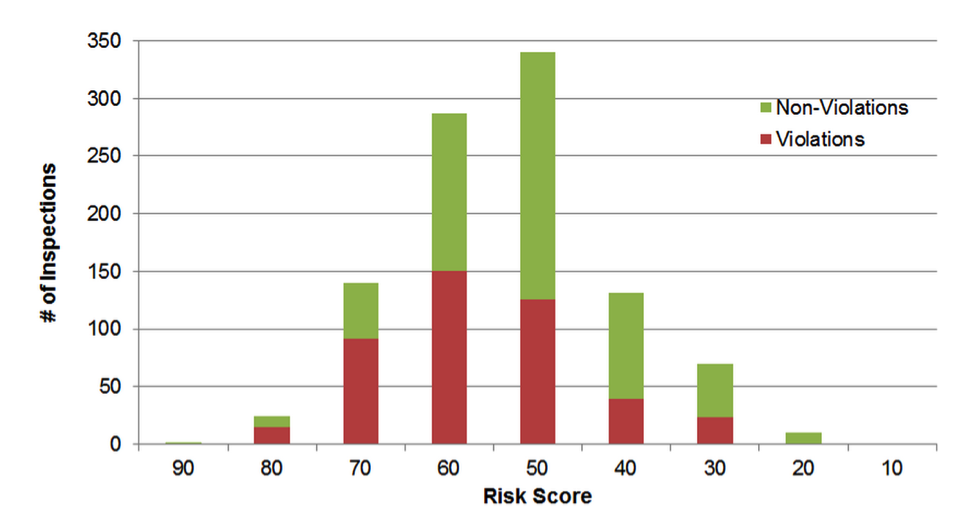
On average, 26% of found violations lead to a formal enforcement, and the average pollutant reduction resulting from a formal enforcement is 3,000 tons per year. Therefore the projected increase in “hit rate” would amount to an average pollutant reduction of 960,000 tons per year, an increase of 620,000 tons from the current estimate of 340,000 tons per year.
What’s next?
The model is a work in progress, and we will continue improving it, both by including more data sources and by refining the way we aggregate information over space and time.
The work we did this summer serves as proof of concept that the use of data science can improve not only the RCRA inspection process, but operations across the entire EPA organization. We are also partnering with Urban Labs to plan and implement a field test to empirically validate the results of the model.