At the Center for Data Science and Public Policy, we work on problems across different policy areas and develop machine learning (ML) solutions that span all these area , from education to public health to government transparency to public safety data. Building machine learning/data science systems often involves coming up with a software workflow and writing variations on very similar code. We can take advantage of that similarity in two ways:
- If you are an experienced data scientist who needs to perform a common ML task, you could implement the entire workflow yourself, but you would generally rather adapt something that somebody else has already written and get on with the more interesting parts of your work.
- If you are not an experienced data scientist but are somewhat tech-savvy and understand your problem and data well, you can rely on best practices in pre-written ML code to make your task easier rather than having to learn all the fundamentals before you can get data, build and evaluate predictive models.
In order to help people ranging from experienced data-hackers to those who would rather think about complex machine learning than code, we’re releasing Diogenes, a set of tools that abstract common machine learning workflows and tasks. Things that Diogenes can do for you include:
- Analyze data from an external source in Python without writing a bunch of extra code to clean the data up.
- Explore data and making pretty graphs.
- Test the performance of different features, classifiers, and subsets of data and fold everything into a nicely formatted report (and data set). You can then analyze that data to figure out which classifier/parameter combination work best for different evaluation metrics that you may care about.
What we do that other tools don’t
Most machine learning Python code cobbles together Pandas and Scikit-Learn to build custom graphs/pipelines/etc. We do not duplicate the functionality of Pandas or Scikit-Learn. Instead, we do the “cobbling together” part so that our users can think of problems from a higher level. For example, users of Scikit-Learn can use grid_search to find the best classifier. Users of Diogenes can find the best classifier, and find how the classifier performs with different-sized data sets, then make a pdf report of the results in only a few lines of code. You don’t have to figure out which classifiers to include in your grid search and which parameter values to sweep over for each classifier – we do it for you.
Call to action
If it sounds like we can save you some work (and, in our humble opinion, we can) check out our project at https://github.com/dssg/diogenes. We welcome feedback, issues, and pull requests.
What’s coming next
This alpha release is focused on getting something out and getting the shell ready. We’re working on three upcoming tasks:
- Getting workflow templates for common machine learning tasks in public policy and social good.
- More comprehensive, automated, parameterized feature generation including aggregate spatiotemporal features.
- More automated temporal cross-validation.
Usage example
import diogenes
import numpy as np
Get data from wine quality data set
data = diogenes.read.open_csv_url(
'http://archive.ics.uci.edu/ml/machine-learning-databases/wine-quality/winequality-white.csv',
delimiter=';')
Note that data is a Numpy structured array We can use it like this:
data.dtype.names
print data.shape
print data['fixed acidity']
We separate our labels from the rest of the data and turn our labels into binary classes.
labels = data['quality']
labels = labels < np.average(labels)
print labels
Remove the labels from the rest of our data
M = diogenes.modify.remove_cols(data, 'quality')
print M.dtype.names
Print summary statistics for our features
diogenes.display.pprint_sa(diogenes.display.describe_cols(M))
0 fixed acidity 4898 6.85478766844 0.843782079126 3.8 14.2 1 volatile acidity 4898 0.278241118824 0.100784258542 0.08 1.1 2 citric acid 4898 0.334191506737 0.12100744957 0.0 1.66 3 residual sugar 4898 6.39141486321 5.07153998933 0.6 65.8 4 chlorides 4898 0.0457723560637 0.0218457376851 0.009 0.346 5 free sulfur dioxide 4898 35.3080849326 17.0054011058 2.0 289.0 6 total sulfur dioxide 4898 138.360657411 42.4937260248 9.0 440.0 7 density 4898 0.99402737648 0.00299060158215 0.98711 1.03898 8 pH 4898 3.18826663944 0.150985184312 2.72 3.82 9 sulphates 4898 0.489846876276 0.114114183106 0.22 1.08
10 alcohol 4898 10.5142670478 1.23049493654 8.0 14.2
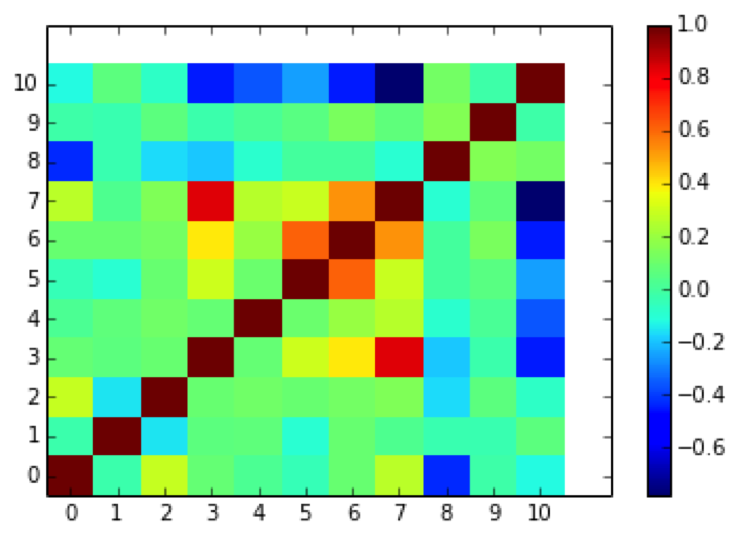
Plot correlation between features
fig = diogenes.display.plot_correlation_matrix(M)
Arrange an experiment trying different classifiers
exp = diogenes.grid_search.experiment.Experiment(
M,
labels,
clfs=diogenes.grid_search.standard_clfs.std_clfs)
trials = exp.run()
Make a pdf report
exp.make_report(verbose=False)
Find the trial with the best score and make an ROC curve
trials_with_score = exp.average_score()
best_trial, best_score = max(trials_with_score.iteritems(), key=lambda trial_and_score: trial_and_score[1])
print best_trial
print best_score
fig = best_trial.roc_curve()
