Introducing the Data@Work Research Hub and Funding Opportunity
With the rapid growth and adoption of technologies like artificial intelligence having uncertain and disparate effects on labor markets, the need for high-quality interdisciplinary research into labor market dynamics and workforce development has never been so urgent.
While new data sources capturing detailed interactions between job seekers, educators, and employers are making it possible to understand the changing dynamics of labor supply and demand with increasing speed and granularity, social science researchers often face significant challenges in accessing and analyzing these large, private, and unstructured sources of labor market data.
With the support of the Alfred P. Sloan Foundation and the JP Morgan Chase Foundation, the University of Chicago’s Center for Data Science and Public Policy (DSaPP) is leading an effort to improve the accessibility and usability of these rich, unstructured, non-public labor market data resources. The Data@Work Research Hub provides free access for academic researchers to newly generated public datasets on labor market dynamics, as well as a secure research environment for working with large databases of non-public resumes, job postings, and employment outcome data.
Data@Work will also be providing research funding for a selected group of proposals for using the new data. We are currently accepting research proposal applications that demonstrate potential uses for these newly available data as well as the limitations, gaps, biases, and suggestions for additions or improvements to the data sets. The 1st round submission is due by September 15, 2017, after which three proposals will be selected to receive a $10,000 research grant to support their work.
Research Challenges
Job vacancy data is rich, both in volume and comprehensiveness. Not only do a large number of job postings show up daily, but each one contains a lot of information. Working with this data unlocks a lot of opportunities for tracking trends in the labor market, such as demand for skills or regional variability in occupations.
A large volume of job vacancy data is not easy to access, and requires a relationship with specific companies. Mixing data from multiple sources compounds this problem. At Data@Work, we work with multiple companies and organizations to build a large protected dataset of job postings , and extract useful data on skills and occupations that we can release to the public.
Data@Work Research Hub
The Data@Work Research Hub is a collection of public datasets produced by the Open Skills Project from job postings data for the purpose of collaborative research. Who can use the Research Hub? Anybody interested in the state of the labor market and how it has differed over time and by region. The datasets currently released have an initial focus on labor demand, but we’re excited to evolve this over time.
Where does the data come from?
Right now, our datasets are based on approximately twenty-seven million job vacancies, spanning 2011–2017 (not all quarters are represented yet, but we’re working on that). This data comes from the National Labor Exchange (23M postings), CareerBuilder (4M postings) and the Commonwealth of Virginia (200,000 postings).
What is being done with the data?
First, we converted all vacancies into a common format for interoperability using the schema from schema.org. They have created a great, simple, open schema for representing job postings, and you can check it out here: http://schema.org/JobPosting
Next, we synthesized the data and created specific data fields with the goal of developing useful datasets. Listed below are a couple of examples of such activities:
- Provide clean job posting title (e.g. Removed the place name from the title)
- Infer the ONET-SOC occupation code from the job posting text
- Infer the Core-Based Statistical Area (CBSA) metro area from the location mentioned in the job posting
- Find occurrences of ONET KSATs (Knowledge, Skills, Abilities, Tools/Technologies) in job posting text
No deduplication has been performed yet, so duplicates between data sources are possible. We are actively working on improving the datasets, as well as computing new attributes for use.
What type of data can be accessed?
The different types of datasets can be found at http://dataatwork.org/data/research/
We provide quarterly datasets grouped by various attributes of the job posting:
- Counts of each raw job title by CBSA and nationwide, with top skills and SOC codes*
- Counts of each cleaned job title by CBSA and nationwide, with top skills and SOC codes*
- Counts of each SOC code* by CBSA and nationwide
*in the true spirit of collaborative research, we are actually including the results of two different versions of our in-progress SOC coder for you to pick from.
Is this data representative of the labor market?
Showing representativeness of job posting data is difficult to show with any confidence. Why? There is no ground truth. Data that we can access has its own bias, and although we can lessen the bias by including as many sources as possible, we cannot measure this concretely.
What can be done? We can compare our data with the Occupational Employment Statistics (OES)(released by the Bureau of Labor Statistics), which contains employment and wage estimates annually for over 800 occupations. These estimates are available for the nation, individual States, metropolitan regions, and nonmetropolitan areas.
Is this good enough? It’s a good start, with the important caveat: OES does not contain job vacancy data!
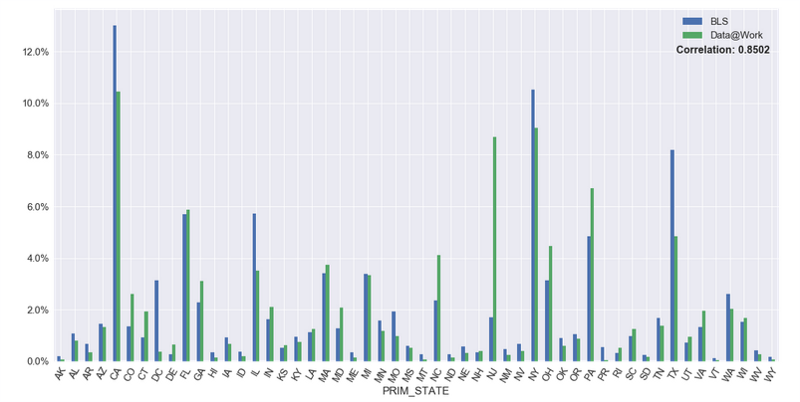
Here are a couple of graphs we produced comparing the two data sources:
Distribution by State
Distribution by Occupation
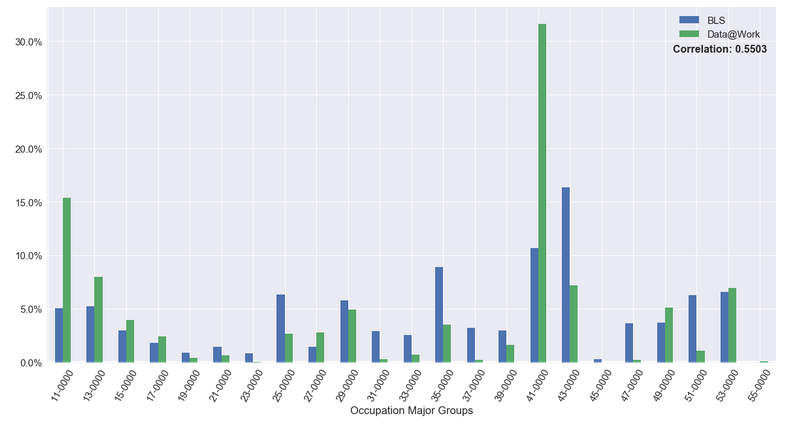
You can view the code that produced this analysis, as well as others, in our open analysis repository.
How is this being improved?
- Compare our data with the BLS JOLTS (Job Openings and Labor Turnover Survey) dataset. Unlike OES, JOLTS actually refers to job vacancies. The problem is that the data is far less granular since they aggregate data into four large regions instead of CBSAs, and by industries instead of occupations.
- Add more job postings to make sure we have sufficient data for each quarter and provide a sample that is more representative of the economy as a whole
- Improve methods for extracting ONET KSATs, finding CBSAs of job postings, inferring SOC codes of job postings, and cleaning job titles
Infer existence of new KSATs, tools, and occupations currently unaddressed by the ONET taxonomy - Expand beyond ONET KSATs to extract other useful items (e.g. detailed work activities, tasks)
Funded Research Opportunity
We’d like you to pick up where we left off! Up to 3 selected research papers will receive a $10,000 research stipend by demonstrating the value of the Data@Work research datasets.
Round 1: Research Abstract
Please use the template found HERE and submit your research plan and paper outline to dsapp.data.at.work@gmail.com. The deadline for this submission is September 15, 2017. We will select up to three participants by September 29 to receive the research stipend and half of the amount ($5,000) will be awarded immediately.
Round 2: Whitepaper
For the participants selected from the 1st round, the remaining $5,000 will be awarded after the white paper is submitted on December 1, 2017
What Can I do Now?
- Sign up to be part of the Data@Work researcher community on Slack
- Explore the data on the Data@Work Research Hub
- Ask questions and provide suggestions for additional datasets to the Data@Work on Slack
- Write an abstract and apply for a research stipend by September 15
Is the code publicly available?
Absolutely. You can browse our github organization — most of our code repositories are open source. We keep certain code private to protect the privacy of our data partners. The code for the research hub is largely located in these two repositories:
- Data Processing and Machine learning methods for the Open Skills Projectgithub.com (workforce-data-initiative/skills-ml)
- Orchestration of data processing tasks to power the Open Skills APIgithub.com (workforce-data-initiative/skills-airflow)
This work is funded by the Alfred P. Sloan Foundation and the JP Morgan Chase Foundation