Introducing the Training Provider Outcomes Toolkit
Trying to find a good job training program can be daunting. How do you know if the skills they teach are valuable in the job market? And how can you be sure they’re doing a good job of teaching those skills? Especially, when the costs can be high. It can feel like a gamble to enroll in a new job training program.
The Open Skills Project aims to collect and provide data to address the first question. At the same time, the Training Provider Outcomes Toolkit (TPOT) aims to help build the tools that can gather and distribute data that can be used to answer the other question.
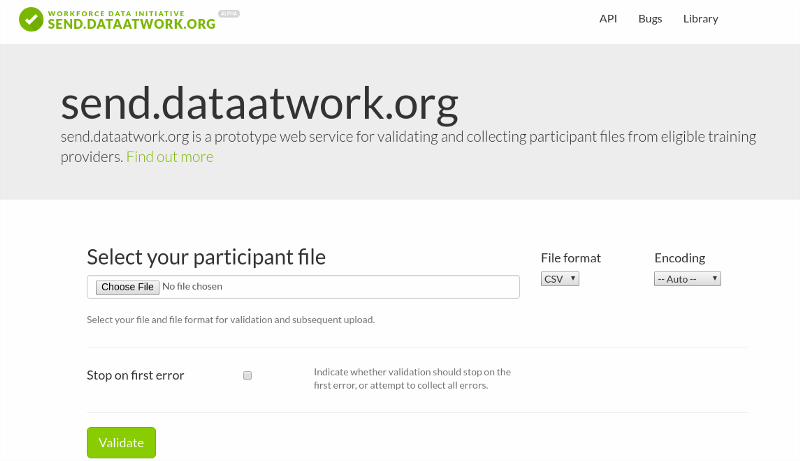
An example of the uploading tool available to workforce boards for collecting outcomes from eligible training providers
Gathering data
We need to know who enrolled and completed every program that each training provider offers. Not only that, but we also need to know how well those individuals are doing after successfully completing the program. This means that we need to go beyond the training providers’ records and find wage and unemployment data.
Gathering all this information is challenging both technically and bureaucratically, but fortunately we have help on the red-tape side of things. The Workforce Innovation and Opportunities Act of 2014 requires performance reports from training providers in order for them to receive federal funding. This mandate is accomplished through state and local workforce development boards, who have the authority to negotiate connections to wage and unemployment databases.
There are hundreds or thousands of training providers within the purview of each workforce development board. Each one must securely upload their participant data to the workforce board in order to be eligible for federal funds. These training providers range from small trade apprenticeships to community colleges to multi-state organizations, with a wide range of data sophistication. The way(s) in which the workforce data boards collect participant outcomes must be easy and accessible to all organizations. At the same time, it must be easy for the board itself to automatically process and validate the datasets.
Hence, we’ve developed a web app that is easy for each workforce board to deploy in order to collect the required data from training providers. Not only does it allow each training provider to upload CSV or Excel files that contain their participant information, but it also validates those files in order to ensure that all the required columns are provided and the data match the constraints. A demo site is online at send.dataatwork.org, and it is easy to use our open source code to deploy custom instances with private S3 repositories and custom requirements.
We’re using Frictionless Data’s open data standards to define the required elements. See our recent interview with them for more information on how we’re using their tools.

An example of the API available for developers to build training provider ‘scorecards’ on aggregated data
Providing the aggregated results
Once the state has collected and aggregated the individual level data into program-level average statistics, the state is mandated to disseminate the aggregated results. We want to help ensure that they do so in a way that is easy for developers to use and build upon for their own apps and services.
On the other side of the toolkit, we’ve developed a simple web app that is designed to connect to a database of the aggregated results and disseminate them using a standard JSON API. Check out the demo site at etp-api.dataatwork.org. A Swagger interface provides documentation and easy-to-use exploration. The general workflow is to first look up a provider, then look up which programs the provider offers, and finally use the pair of IDs for the provider and a given program to look at its “scorecards” for the past few years. Just like the uploader site, this site is open source and easy to deploy customized versions.
What’s next?
These two tools just provide the entry and exit points for a much larger data processing toolchain. We hope that these tools will be helpful to state and local workforce boards in their effort to collect, aggregate and disseminate data on training providers in a way that the community can use and build upon. We also anticipate that state workforce boards will need to do messy data matching between the providers’ participant files and their wage and unemployment data — our pgdedupe tool may be useful for that task. And they will need to put together a complete pipeline to aggregate the results together and censor values where there aren’t sufficient entries to ensure privacy.
Stay tuned for updates here!
This work is funded by the Alfred P. Sloan Foundation and the JP Morgan Chase Foundation